
Blog
Wir leben in einer Welt der Daten: Es gibt mehr davon als je zuvor in einer unaufhörlich wachsenden Anzahl von Formen und Orten. Umgang mit Daten ist Ihr Fenster in die Art und Weise, wie Datenteams die Herausforderungen dieser neuen Welt angehen, um ihren Unternehmen und Kunden zu helfen, erfolgreich zu sein.
Streaming Data Analytics wird voraussichtlich bis zu einem Markt von 38,6 Milliarden US-Dollar wachsen 2025. Die Welt bewegt sich schneller als je zuvor, und Unternehmen, die große Mengen sich schnell ändernder oder wachsender Daten verarbeiten, müssen sich weiterentwickeln, um Schritt zu halten – insbesondere mit dem Wachstum der IoT-Geräte (Internet of Things) in unserer Umgebung. Echtzeit-Einblicke bieten Unternehmen einzigartige Vorteile, die schnell zu einem Muss werden, um in einer Vielzahl von Märkten wettbewerbsfähig zu bleiben. Schauen wir uns einige Möglichkeiten an, wie verschiedene Branchen Streaming-Daten nutzen können.

Wie Branchen von Streaming-Daten profitieren können
- Vertrieb, Marketing, Ad-Tech: Schnellere Marketingentscheidungen treffen, Werbeausgaben optimieren [19659009] Sicherheit, Betrugserkennung: Verkürzung des Zeitaufwands für die Erkennung und Reaktion auf böswillige Bedrohungen
- Herstellung, Lieferkettenmanagement: Erhöhung der Bestandsgenauigkeit, Vermeidung von Ausfallzeiten der Produktionslinie, Überwachung des aktuellen IoT und der Maschinen-zu- Maschinendaten
- Energie, Versorgungsunternehmen: Analysieren von IoT-Daten, um Geräteprobleme zu alarmieren und zu beheben, potenzielle Probleme zu lösen und Wartungskosten zu senken
- Finanzen, Fintech: Nachverfolgen des Kundenverhaltens, Analysieren von Kontoaktivitäten, Sofort und proaktiv auf Betrug und Kundenbedürfnisse reagieren, während sie beschäftigt sind.
- Automotive: Überwachung vernetzter, autonomer Autos in Echtzeit zur Optimierung der Routen zur Vermeidung von Verkehr und zur Diagnose mechanischer Probleme.
Da Echtzeitanalysen und die Verarbeitung von maschinellem Lernstrom schnell zunehmen, wird ein neuer Satz eingeführt von technologischen und konzeptionellen Herausforderungen. In diesem Artikel werden wir uns mit diesen Herausforderungen befassen und wie Upsolver und Sisense sie angehen.
Technologische Herausforderungen beim Umgang mit Streaming-Daten
Stateful Transformationen
Eine der Hauptherausforderungen beim Umgang mit Streaming-Daten kommt von Durchführung zustandsbezogener Transformationen für einzelne Ereignisse. Im Gegensatz zu einem Stapelverarbeitungsjob, der in einem isolierten Stapel mit eindeutigen Start- und Endzeiten ausgeführt wird, wird ein Stream-Verarbeitungsjob bei jedem Ereignis separat ausgeführt. Vorgänge wie API-Aufrufe, Joins und Aggregationen, die früher alle paar Minuten / Stunden ausgeführt wurden, müssen jetzt viele Male pro Sekunde ausgeführt werden. Um diese Herausforderung zu bewältigen, muss der relevante Kontext auf den Verarbeitungsinstanzen (Statusverwaltung) mithilfe von Techniken wie gleitenden Zeitfenstern zwischengespeichert werden.
Optimieren der Objektspeicherung
Ein weiteres Ziel, das Teams, die sich mit Streaming-Daten befassen, möglicherweise haben, ist das Verwalten und Optimieren eines Dateisystems auf Objektspeicher. Streaming-Daten sind in der Regel sehr umfangreich und daher teuer in der Speicherung. Cloud-Objektspeicher ist jedoch wie Amazon S3 eine sehr kostengünstige Lösung (ab 23 USD pro Monat und Terabyte für Hot-Storage zum Zeitpunkt des Schreibens) im Vergleich zu herkömmlichen Datenbanken und Kafka (das standardmäßig drei Replikate auf lokalem Speicher erstellt). Das sind viele Daten, die gespeichert werden!).
Die Herausforderung bei der Objektspeicherung besteht in der Komplexität der Optimierung des Dateisystems durch Kombination des richtigen Dateiformats, der richtigen Komprimierung und der richtigen Größe. Zum Beispiel sind kleine Dateien ein Leistungs-Anti-Pattern für die Objektspeicherung (50-fache Auswirkung), aber die Verwendung von Streaming-Daten zwingt uns, solche Dateien zu erstellen.
Bereinigen schmutziger Daten
Jeder Datenprofi weiß, dass die Sicherstellung der Datenqualität für die Erstellung brauchbarer Abfrageergebnisse von entscheidender Bedeutung ist. Das Streaming von Daten kann in dieser Hinsicht eine besondere Herausforderung darstellen, da es in der Regel „schmutzig“ ist und neue Felder ohne Vorwarnung und häufige Fehler beim Datenerfassungsprozess hinzugefügt werden. Um die Lücke zu analytikfähigen Daten zu schließen, müssen Entwickler in der Lage sein, Datenqualitätsprobleme schnell zu lösen.
Die beste Architektur dafür heißt „Event Sourcing“. Um dies zu implementieren, sind ein Repository aller Rohereignisse, ein Schema beim Lesen und eine Ausführungsengine erforderlich, die Rohereignisse in Tabellen umwandelt. Jedes Mal, wenn Analysedaten angepasst werden müssen, führt der Entwickler einen Verarbeitungsjob aus dem Rohdaten-Repository aus (Zeitreise / Wiedergabe / Wiederaufbereitung).
Weitergehende Überlegungen
Dies sind nur einige der technischen Überlegungen, die Teams benötigen zu versuchen, wenn Sie versuchen, Echtzeitdaten zu verwenden. Sie müssen auch große Auftragsvolumina orchestrieren, um sich schnell ändernde Daten zu verarbeiten, die Datenkonsistenz bei genau einmaliger Verarbeitung sicherzustellen
und gleichzeitig Anfragen einer Vielzahl von Benutzern zu bearbeiten, die alle versuchen, Einblicke aus denselben Daten im Internet zu erhalten gleichzeitig.

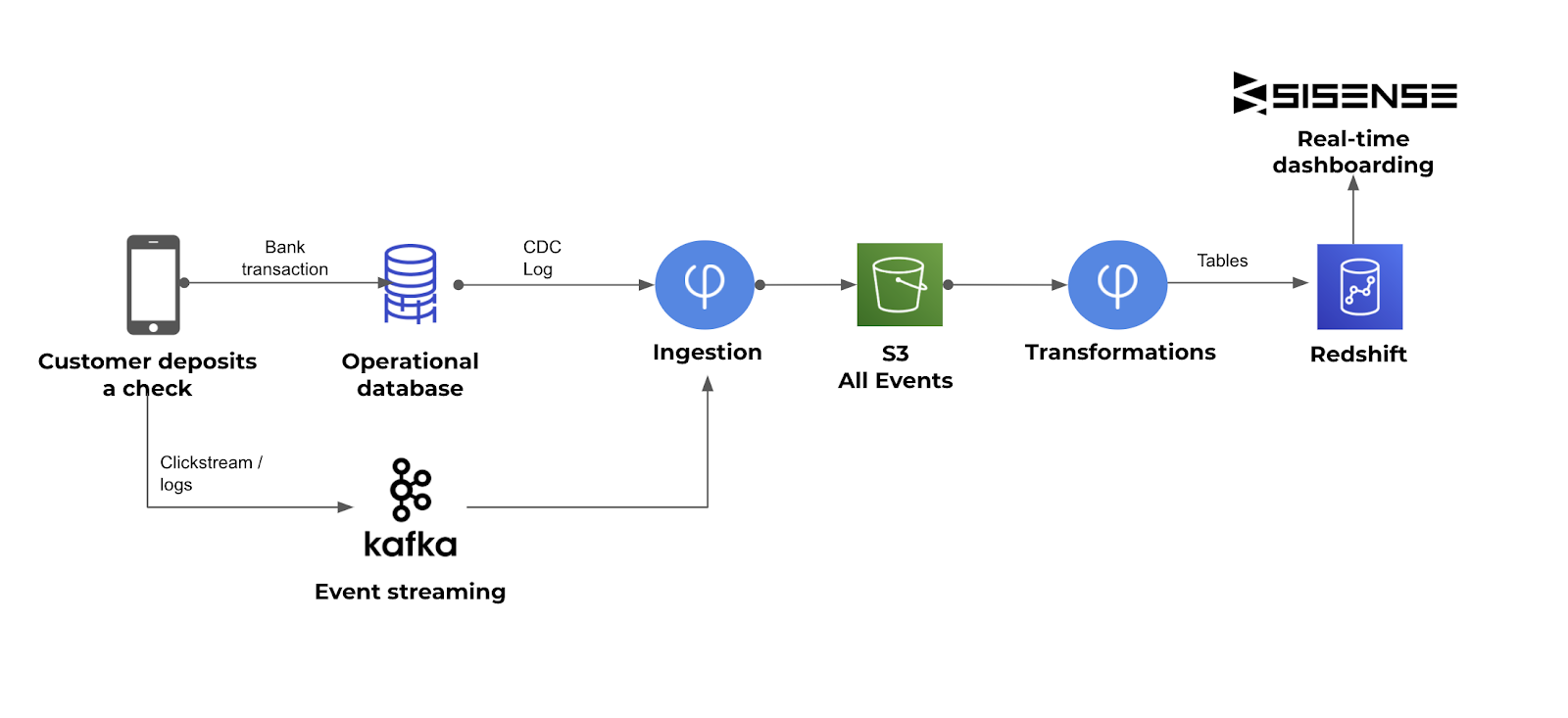
Herausforderungen wie Job-Orchestrierung, genau einmalige Datenkonsistenz und Dateisystemverwaltung sind große technische Herausforderungen . Ihre Lösung ist eine komplexe Herausforderung, die zu einem Data Engineering-Engpass führt, der den Analyseprozess verlangsamt.
Upsolver kapselt die Komplexität des Streaming-Engineerings, indem jeder technische Benutzer (Dateningenieure, Datenbankadministratoren, Analysten, Wissenschaftler, Entwickler) in die Lage versetzt wird, Streaming-Daten für die Analyse aufzunehmen, zu ermitteln und vorzubereiten. Diese Experten können Transformationen von Streams zu Tabellen definieren und den Verarbeitungsfortschritt über eine visuelle, SQL-basierte Schnittstelle steuern. Die technische Komplexität wird vom Benutzer über eine Ausführungs-Engine abstrahiert, die mehrere Datenquellen (Stream und Batch) in Tabellen in verschiedenen Datenbanken umwandelt.
Lassen Sie uns untersuchen, wie es funktioniert!
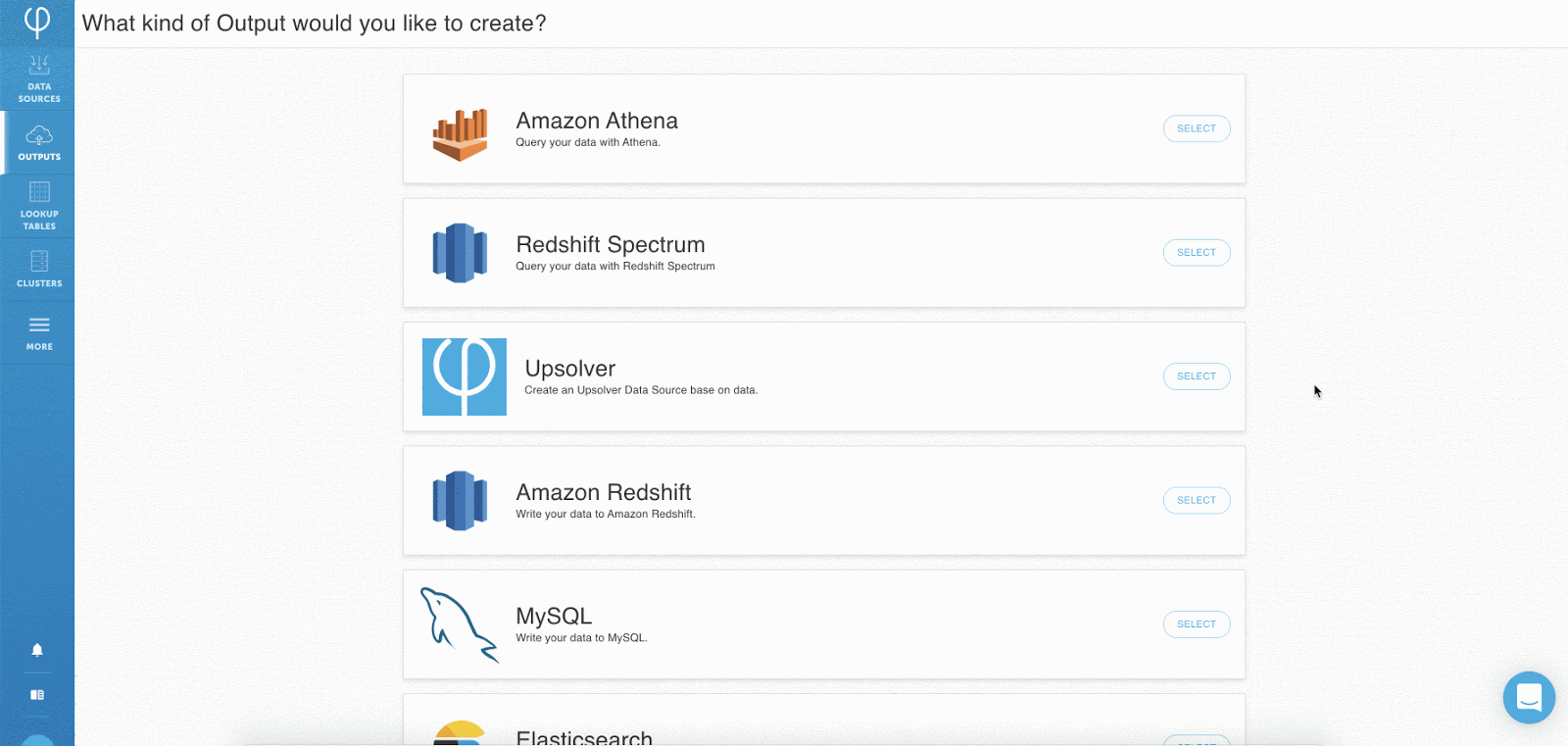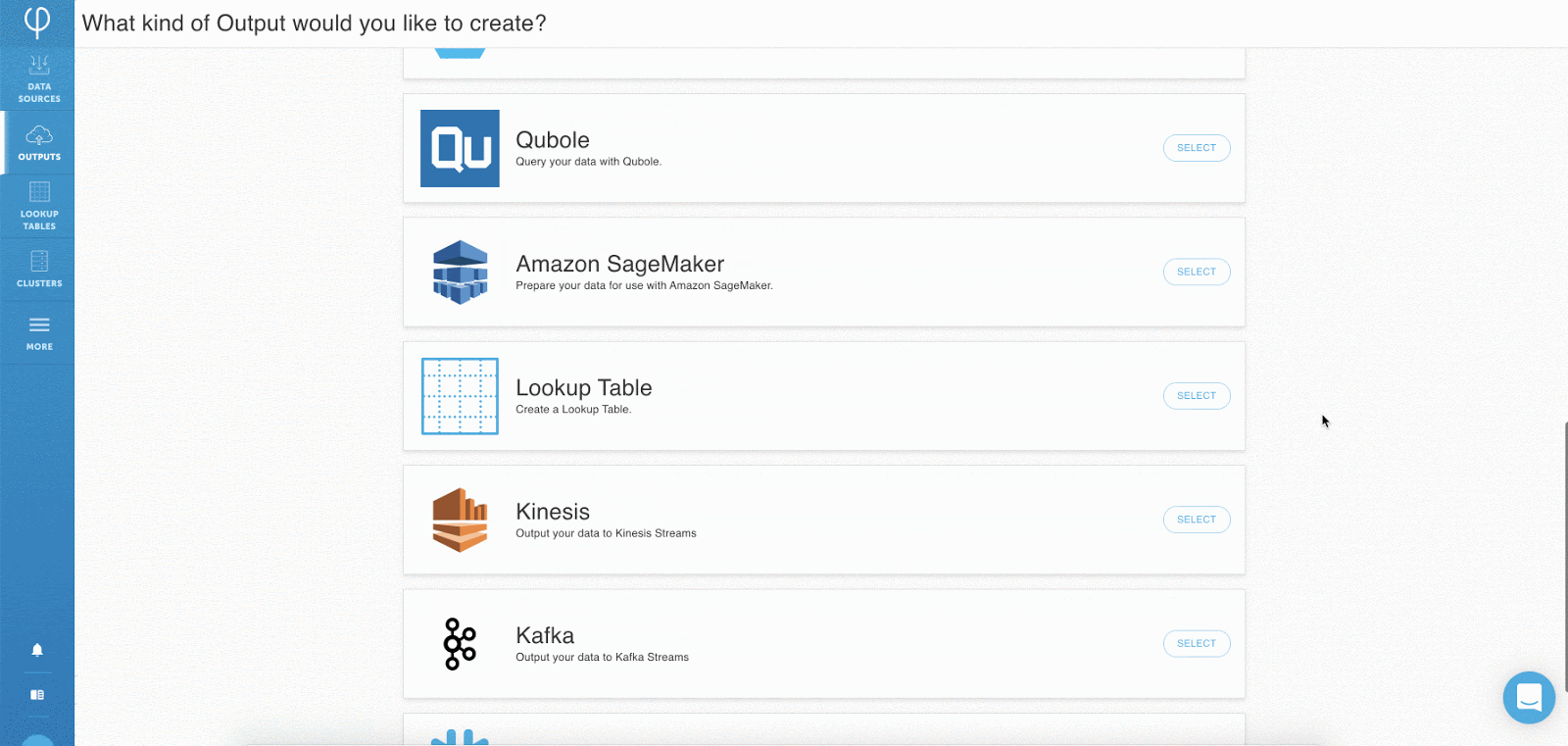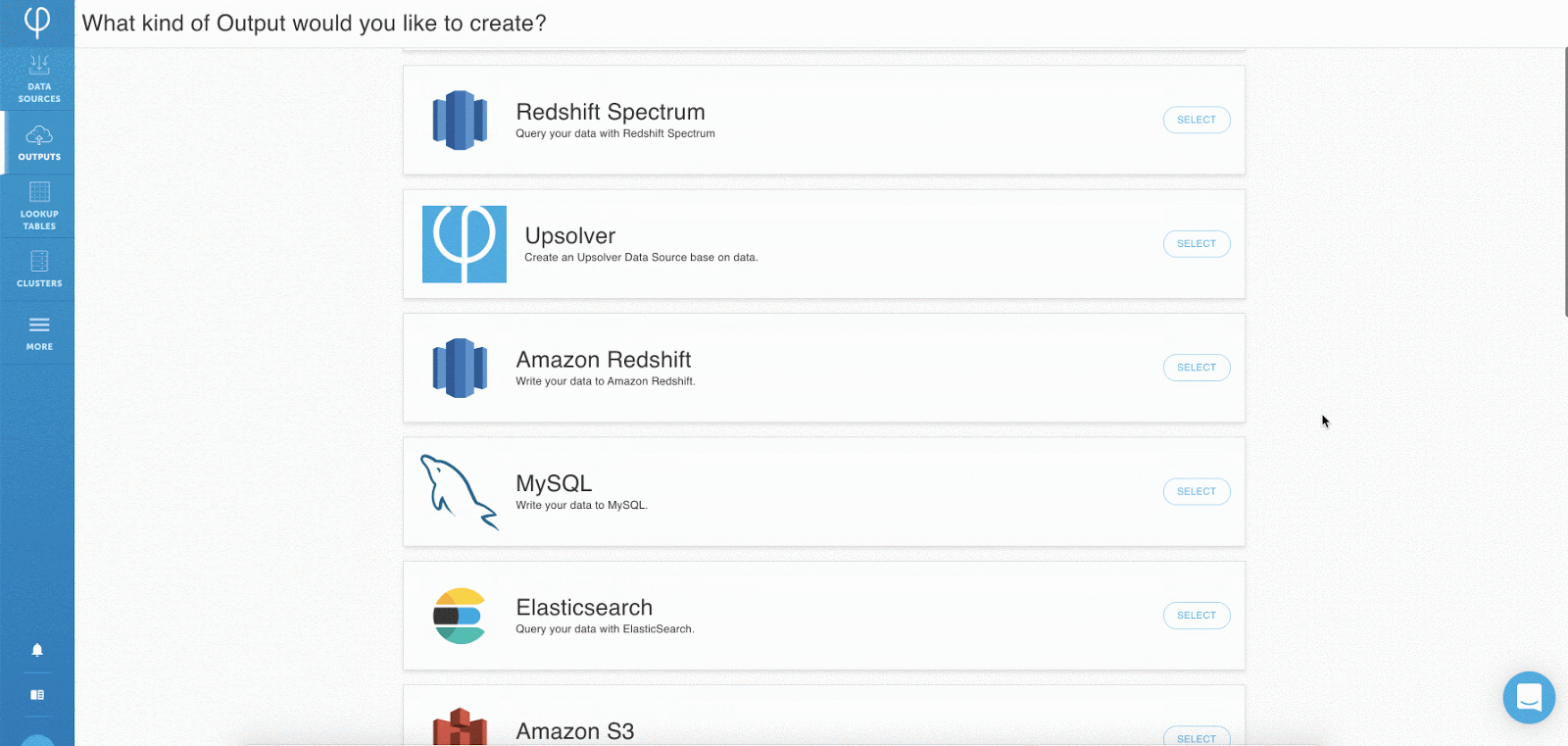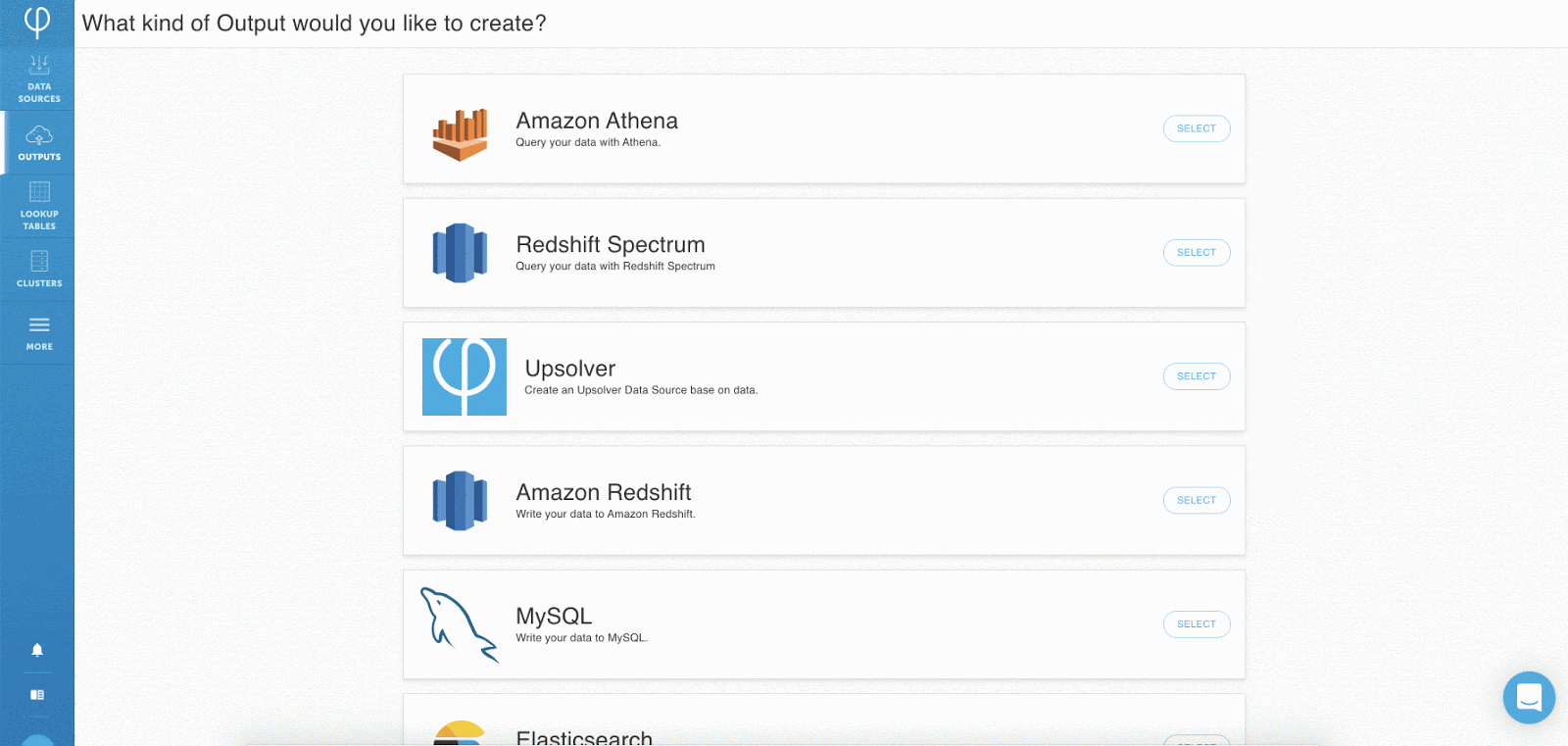
Schritt 1: Herstellen einer Verbindung zu Datenquellen – Cloud-Speicher, Datenströme, Datenbanken
Sobald Benutzer sich in Ihrer Upsolver-Benutzeroberfläche befinden, klicken Sie einfach auf „Neue Daten hinzufügen“ source “und wählen Sie einen der integrierten Konnektoren für Cloud-Speicher, Datenbanken oder Streams. Über die Benutzeroberfläche können Benutzer ihre Quelldaten in Formaten wie JSON, CSV, Avro, Parkett und Protobuf analysieren.

Vor Beginn der Aufnahme wird ein Beispiel aus den analysierten Daten angezeigt:
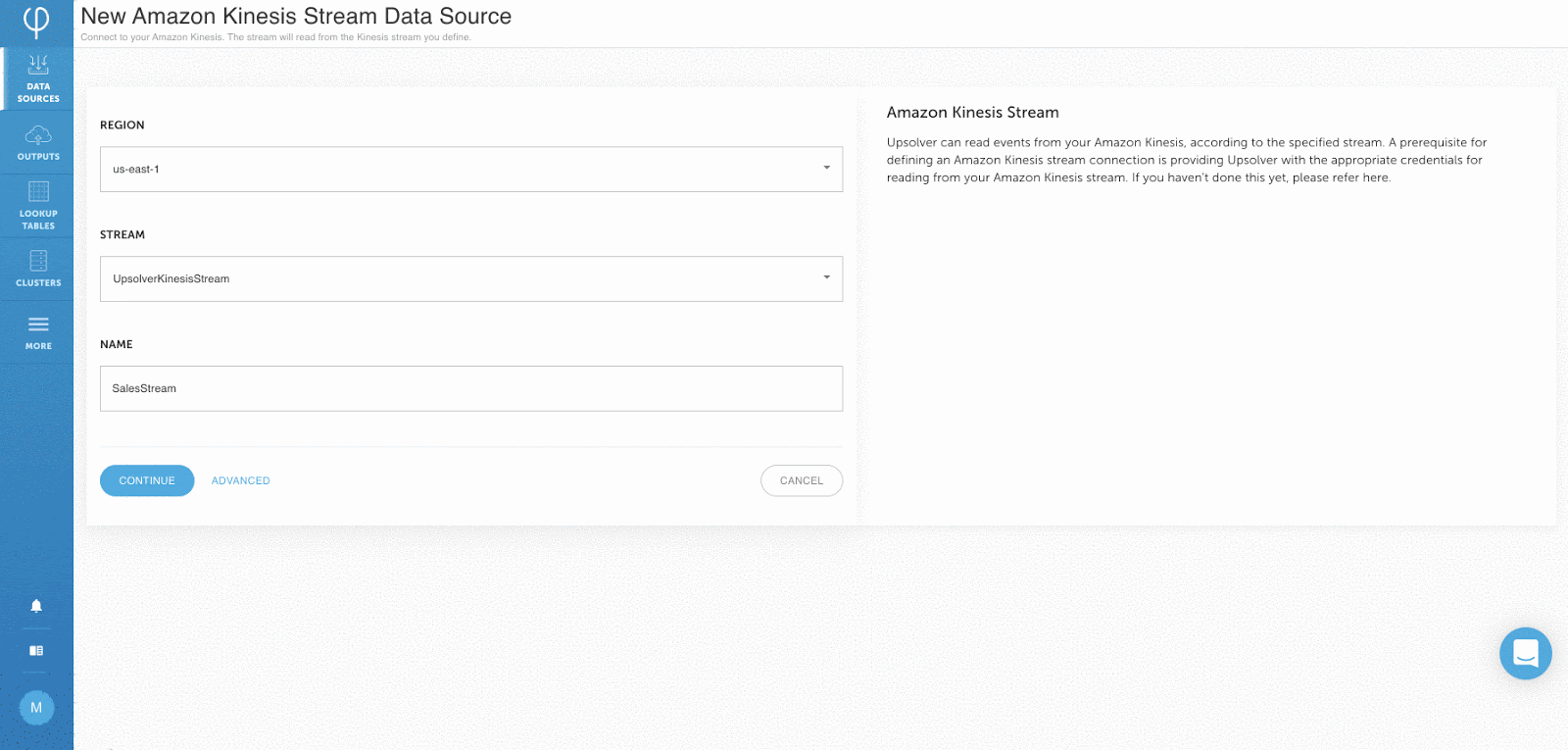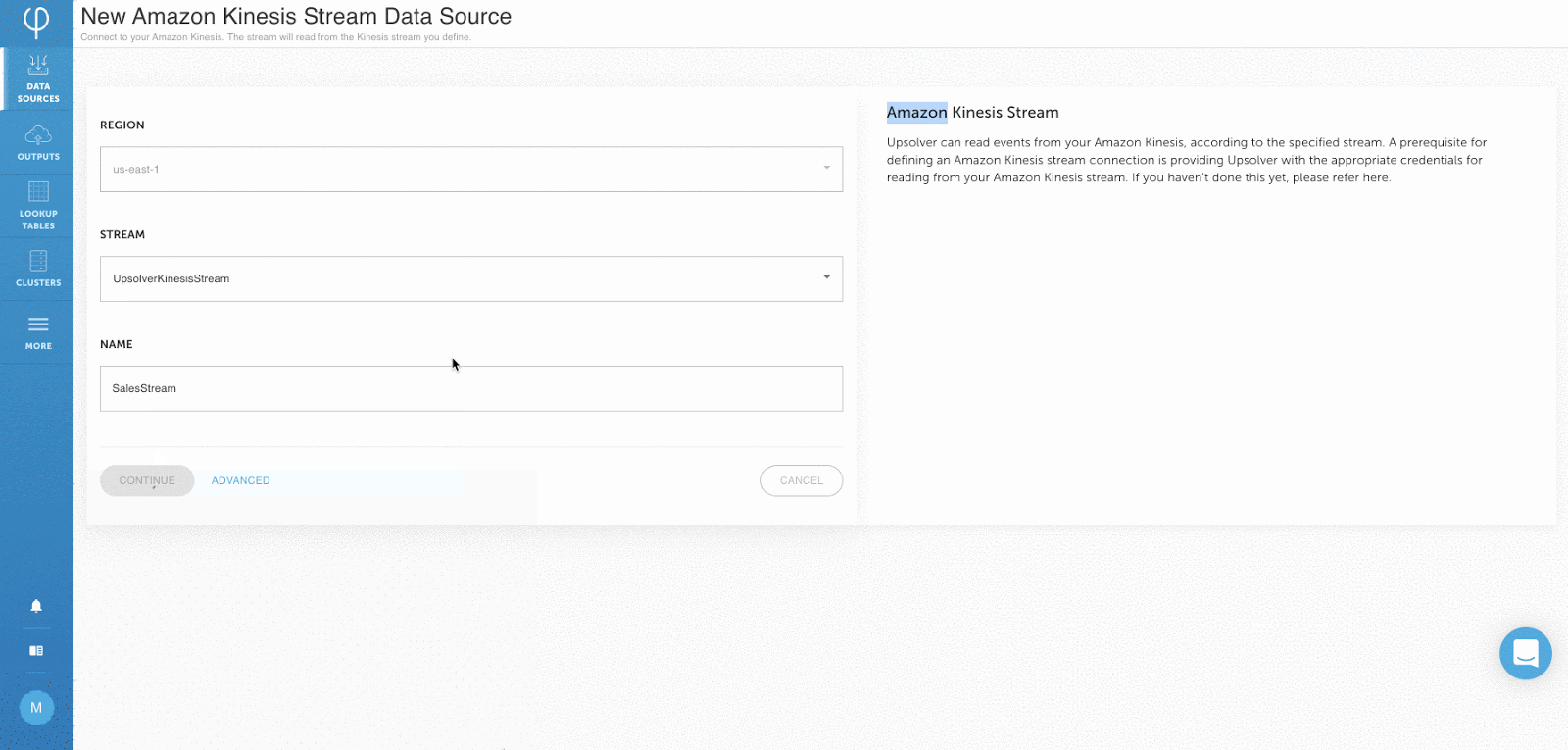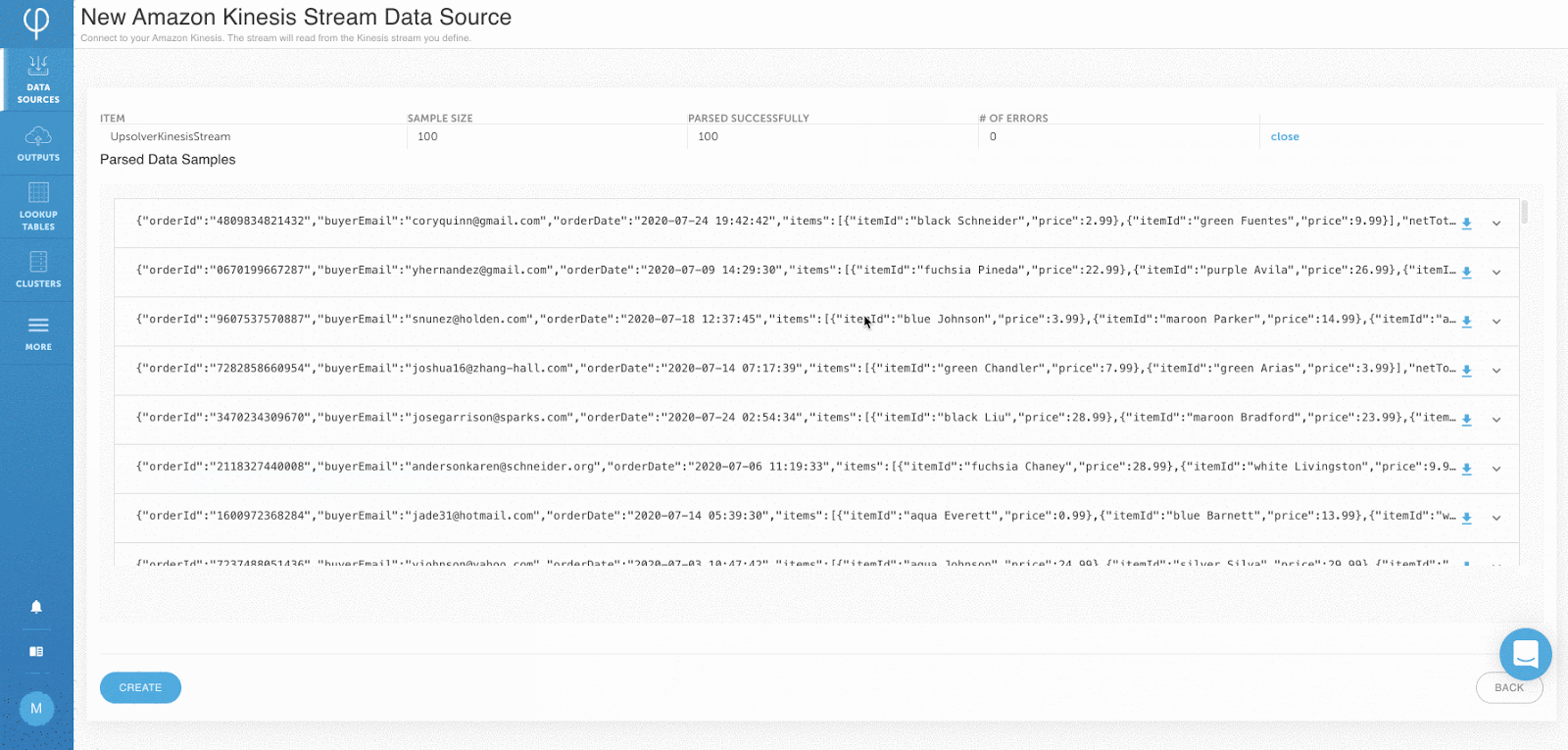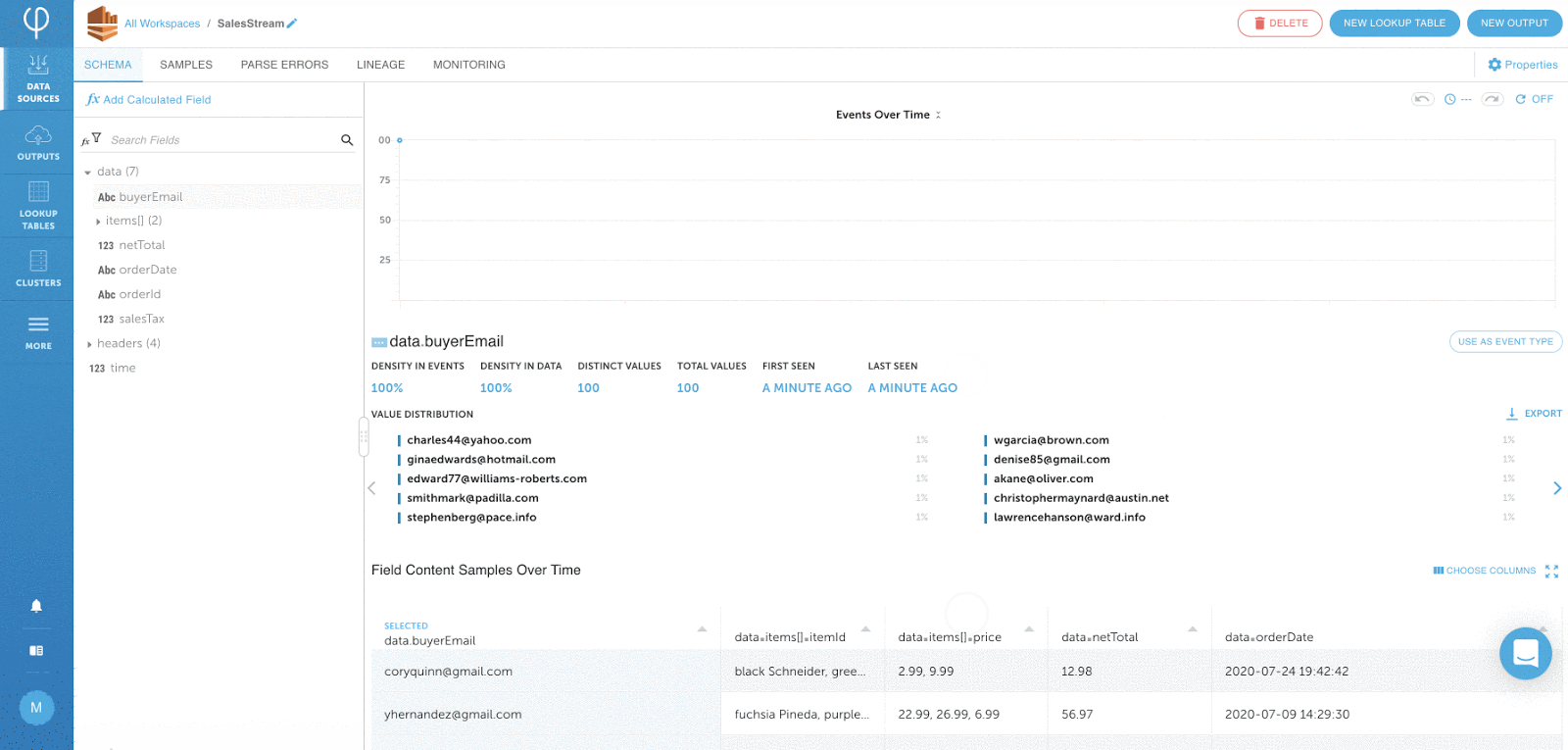
Schema ein Lese- und Statistikdaten pro Feld werden automatisch erkannt und dem Benutzer angezeigt:

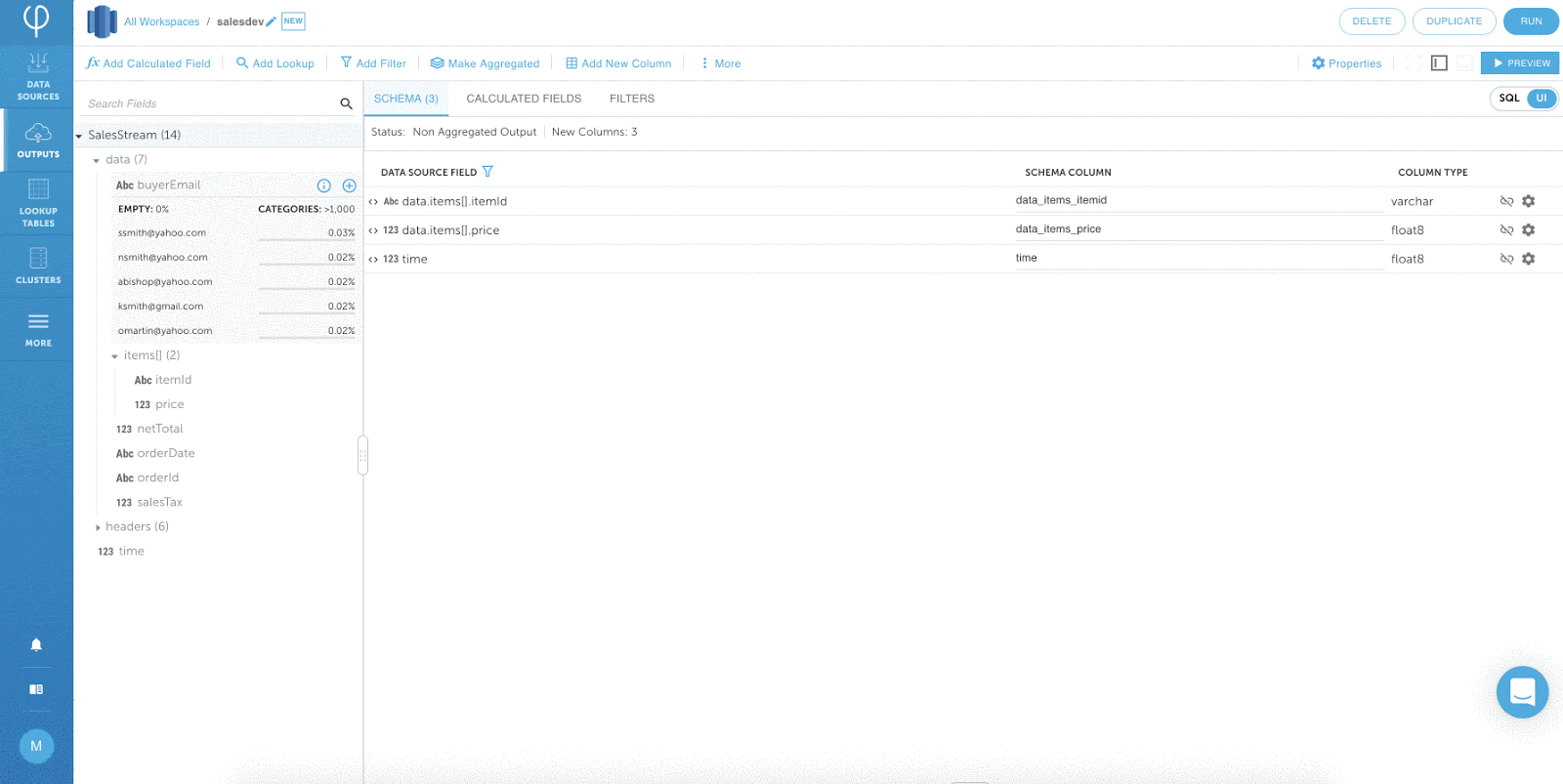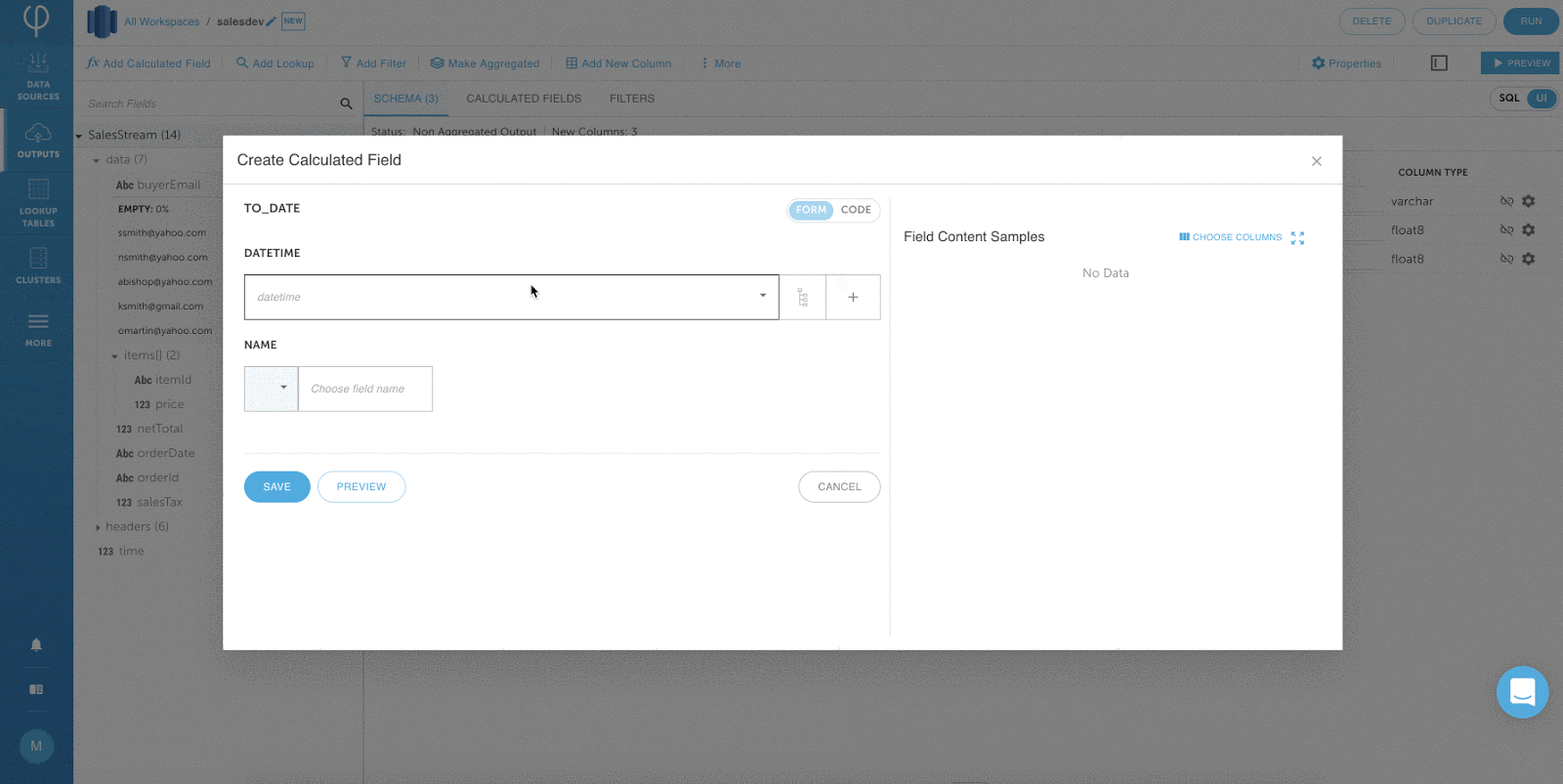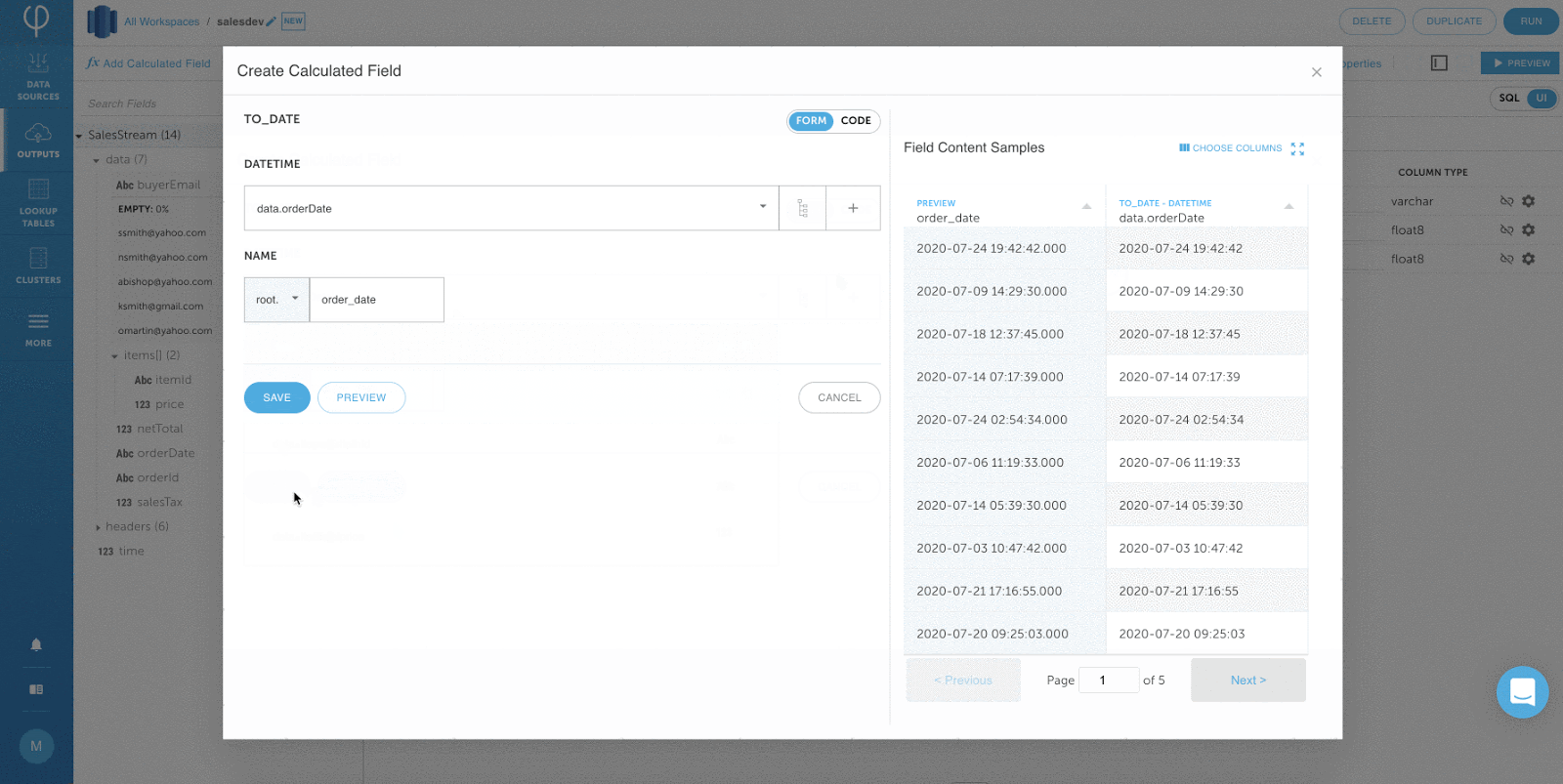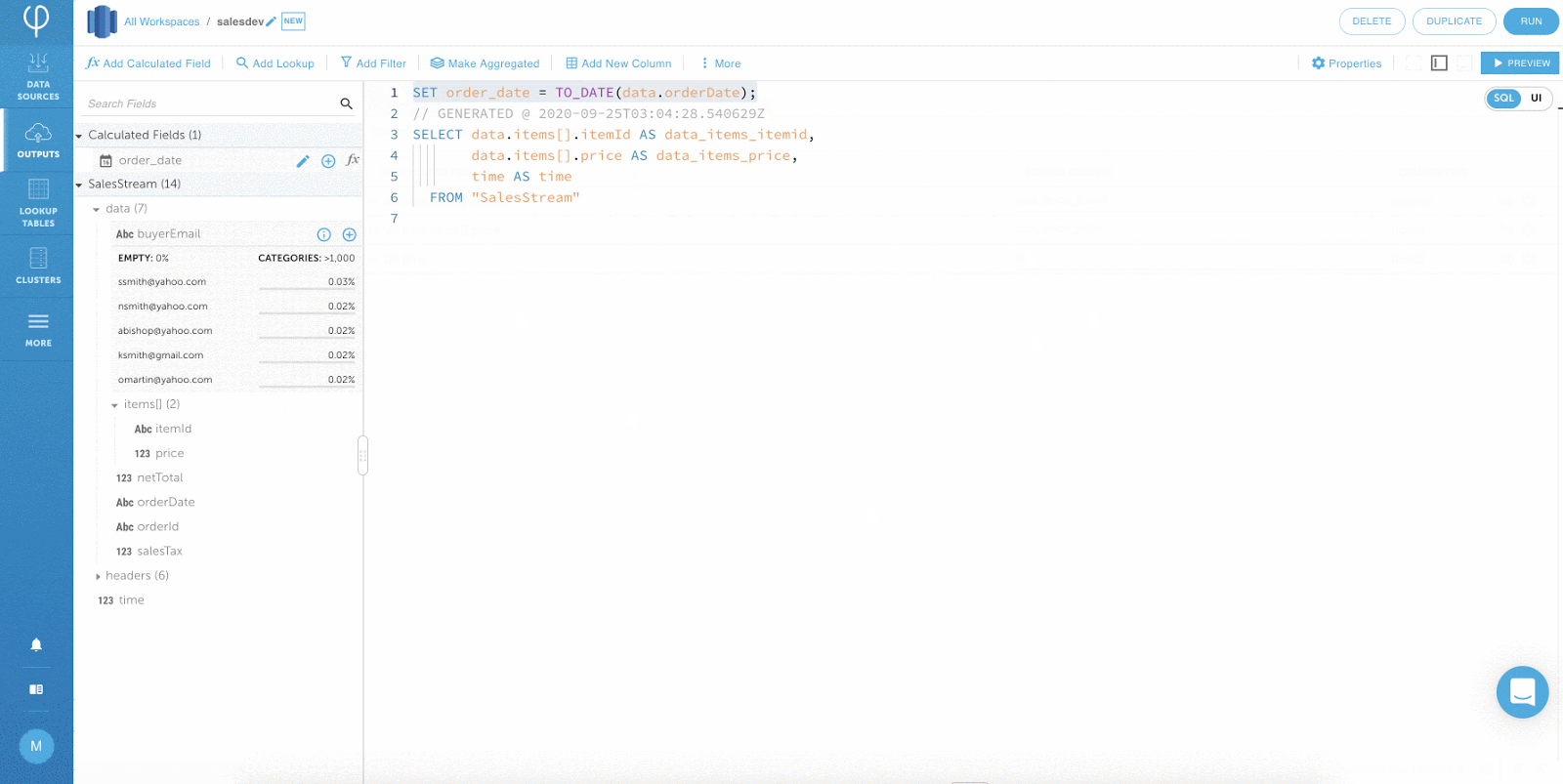
Schritt 2: Definieren zustandsbehafteter Transformationen
Nachdem jede Datenquelle eingerichtet wurde, ist es an der Zeit, eine Ausgabe als Upsolver-Entität zu definieren zur Bearbeitung von Aufträgen. Jede Ausgabe erstellt eine Tabelle in einer Zielsynchronisierung und füllt sie kontinuierlich mit Daten, die auf den vom Benutzer definierten Transformationen basieren.
Transformationen können über die Benutzeroberfläche, SQL oder beides definiert werden (bidirektionale Synchronisierung zwischen Benutzeroberfläche und SQL).
(Hinweis: Die SQL-Anweisung dient nicht zum Abfragen von Daten wie in Datenbanken. In Upsolver, SQL wird verwendet, um fortlaufende Verarbeitungsjobs zu definieren, sodass die SQL-Anweisung für jedes Quellereignis einmal ausgeführt wird.)
Upsolver bietet über 200 integrierte Funktionen und sofort einsatzbereite ANSI SQL-Unterstützung, um die Stream-Verarbeitung zu vereinfachen. Diese nativen Funktionen verbergen die Komplexität der Implementierung vor den Benutzern, sodass ihre Zeit nicht mit benutzerdefinierter Codierung verschwendet wird.
Upsolver bietet auch statusbehaftete Transformationen, mit denen der Benutzer das aktuell verarbeitete Ereignis mit anderen Datenquellen verknüpfen, die Aggregation (mit und ohne Zeitfenster) ausführen und ähnliche Ereignisse deduplizieren kann.
Hinzufügen von Transformationen über die Benutzeroberfläche:
Bearbeiten von Transformationen mit SQL:
Die folgende Ausgabe berechnet die Auftragssumme durch Aggregation der Nettosumme und der Umsatzsteuer.
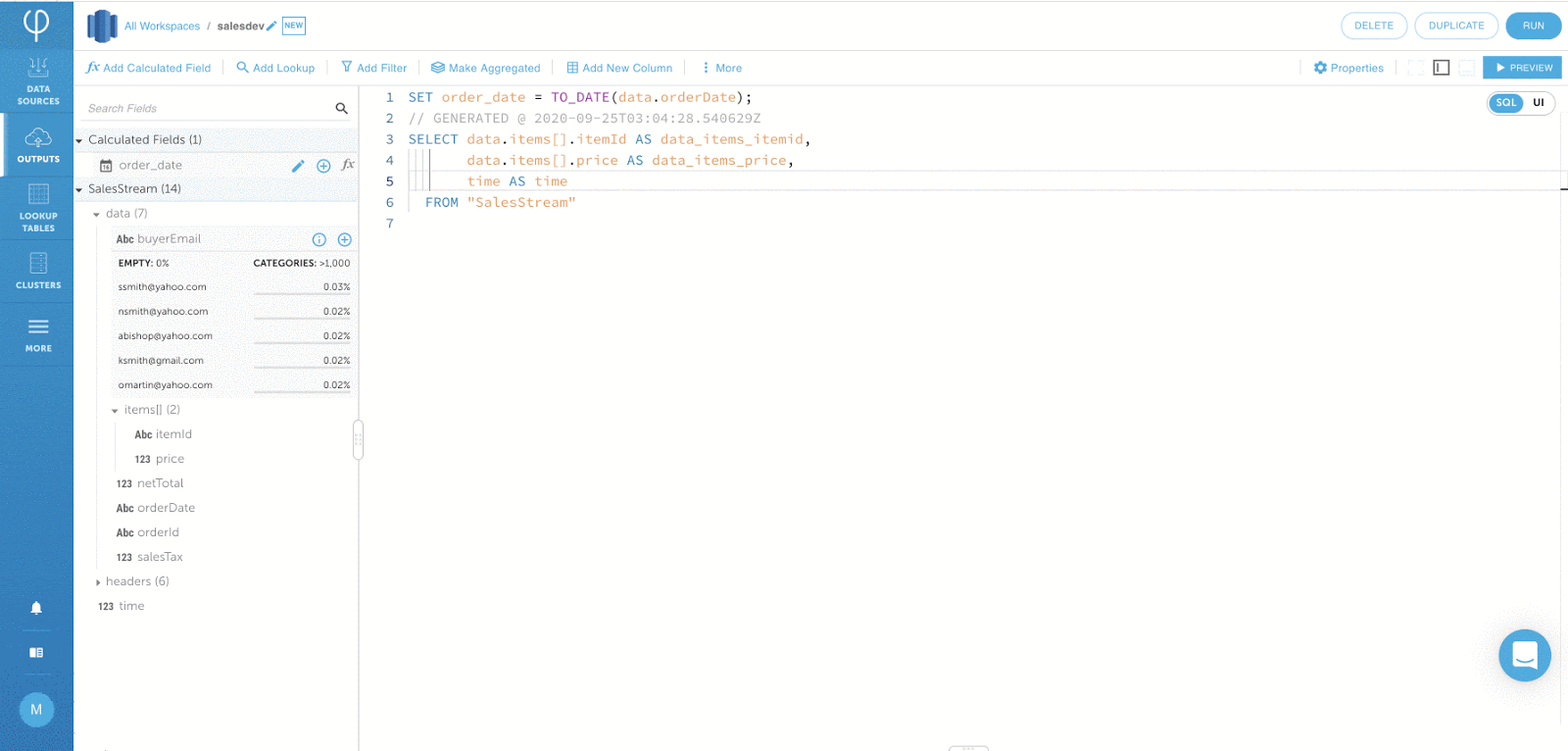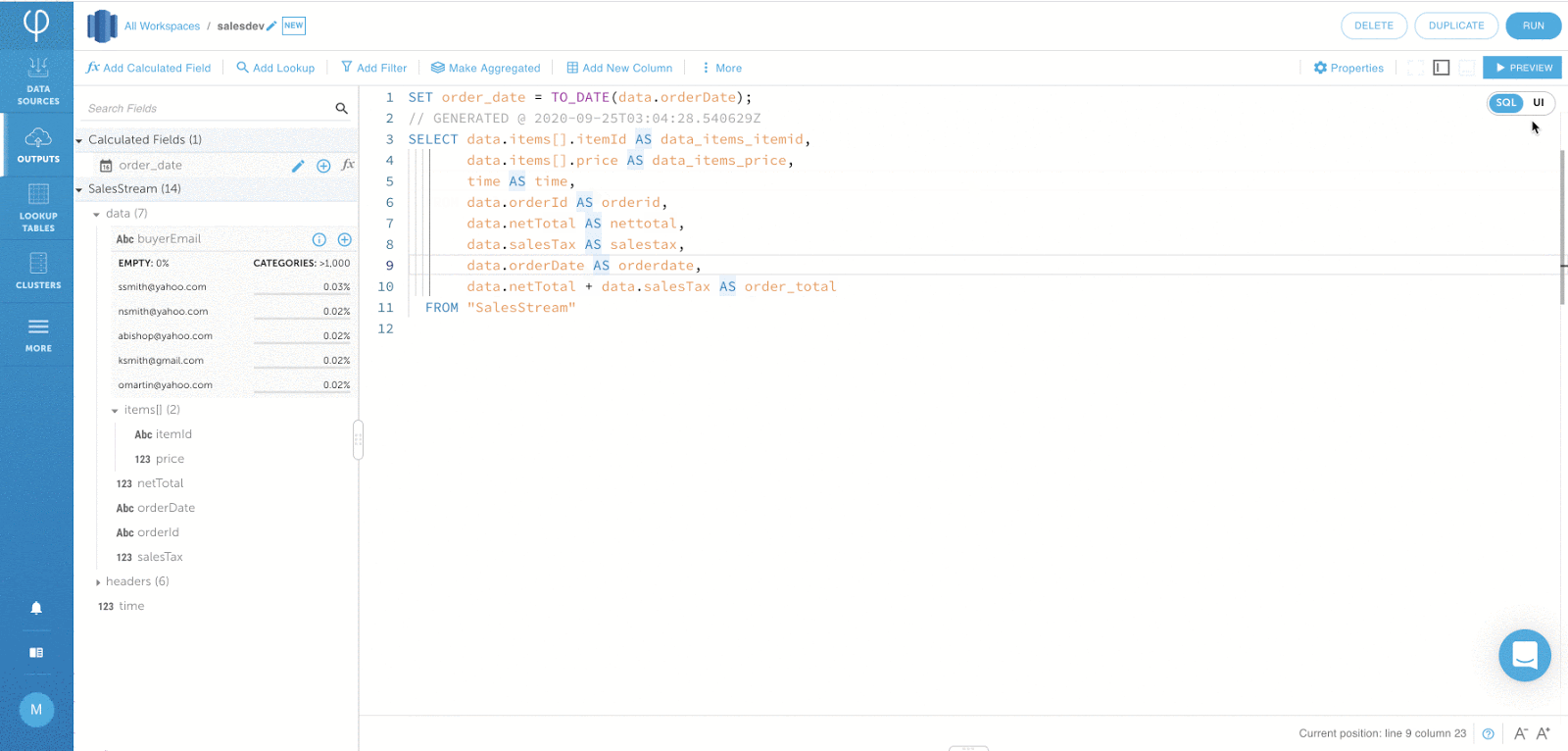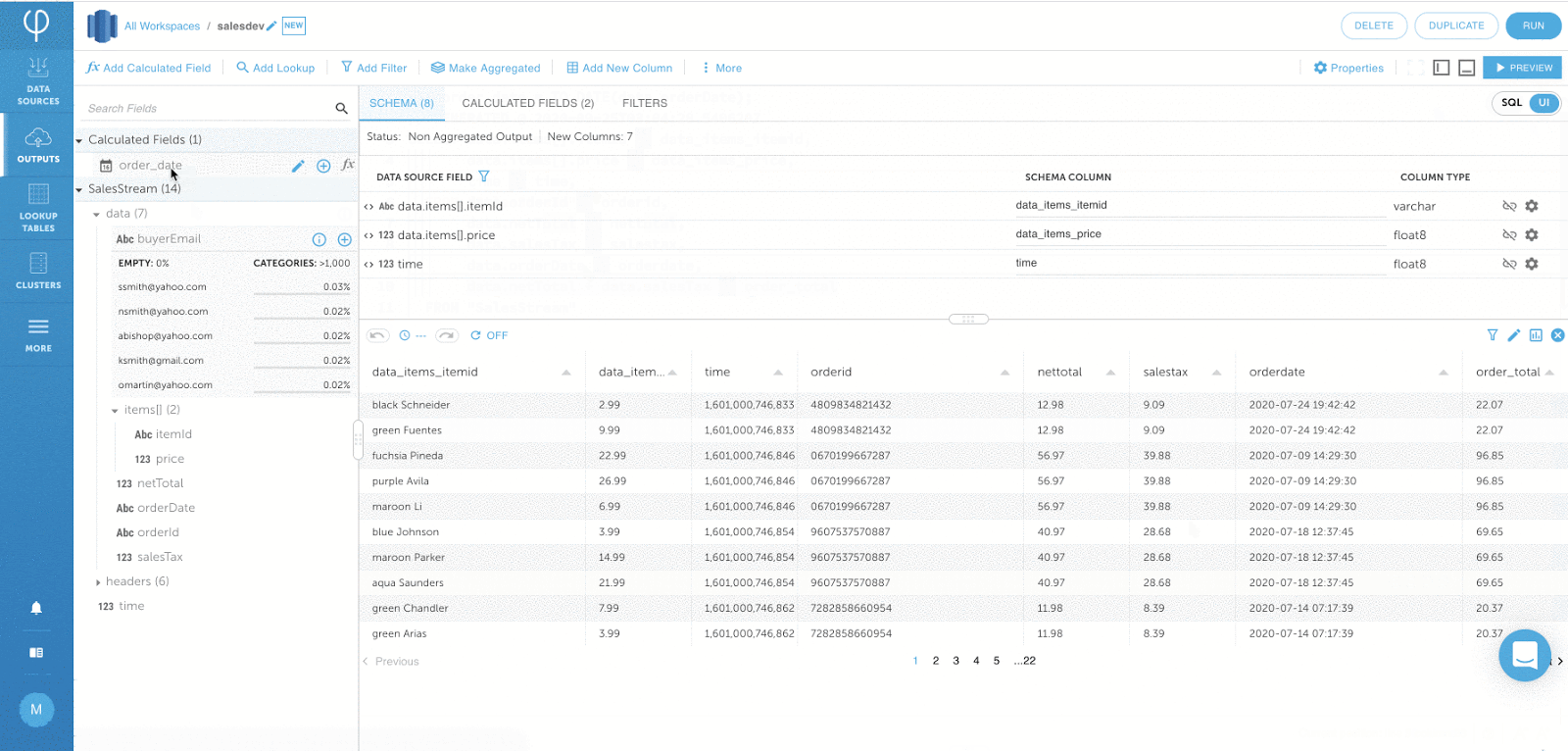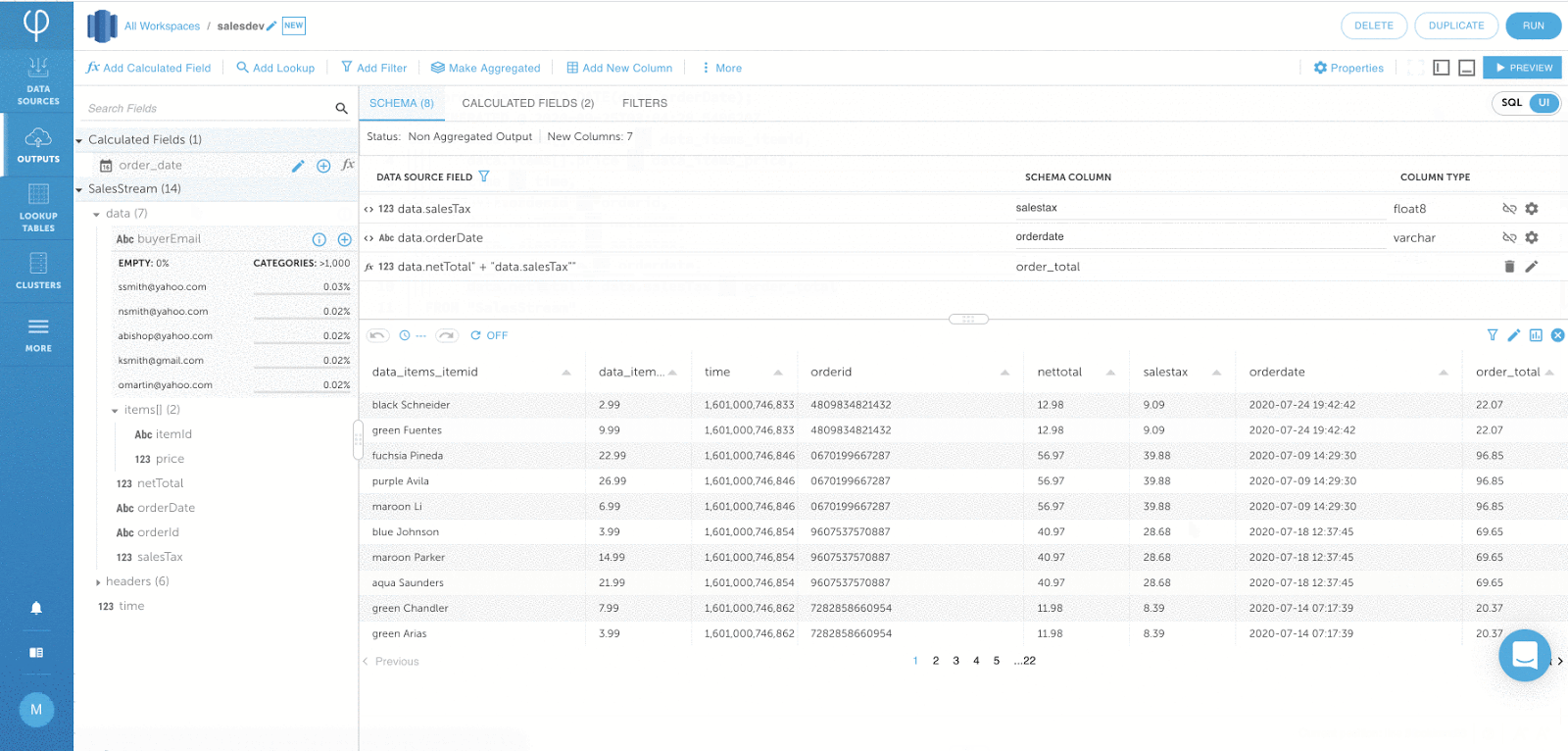
IF_DUPLICATE-Funktion für Filtern ähnlicher Ereignisse:
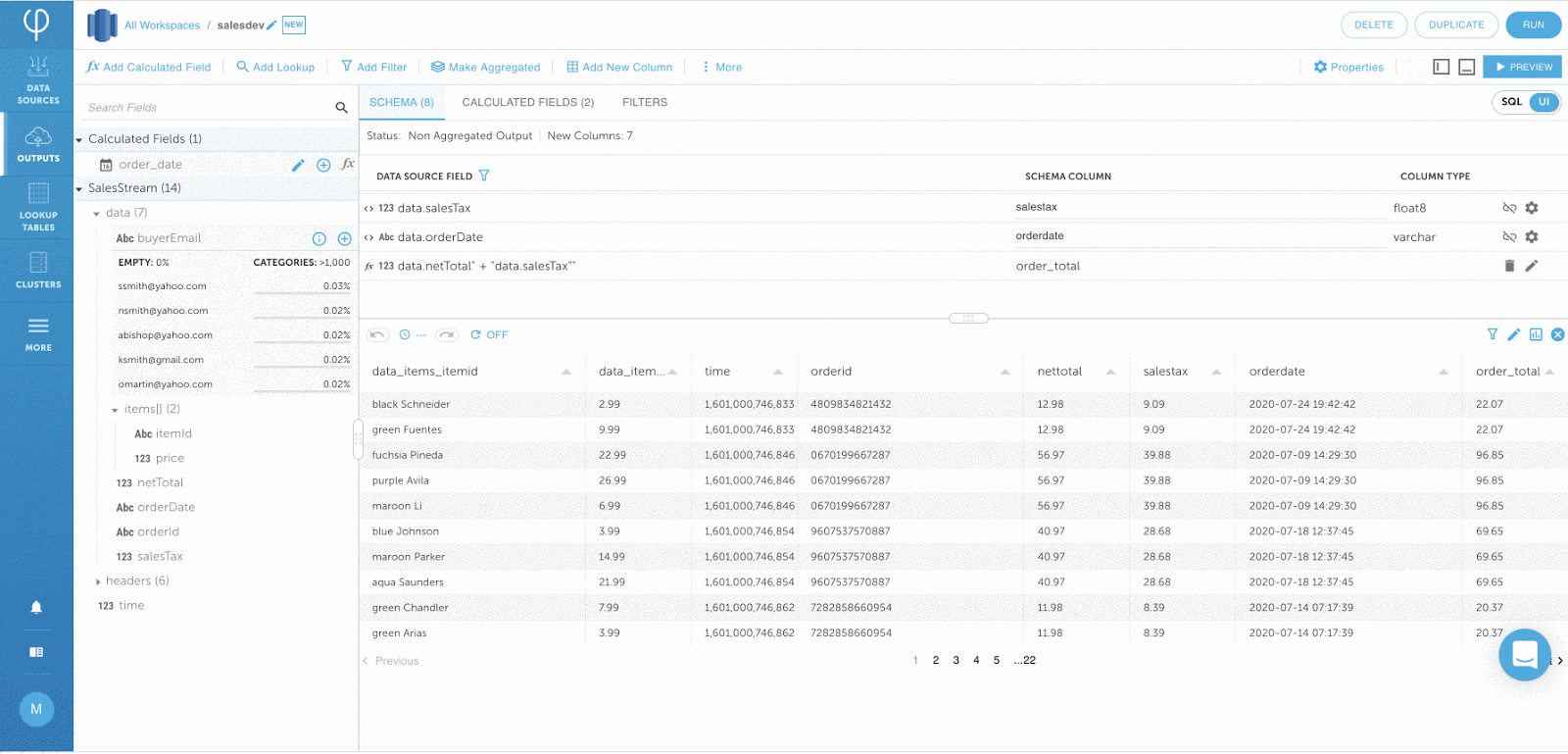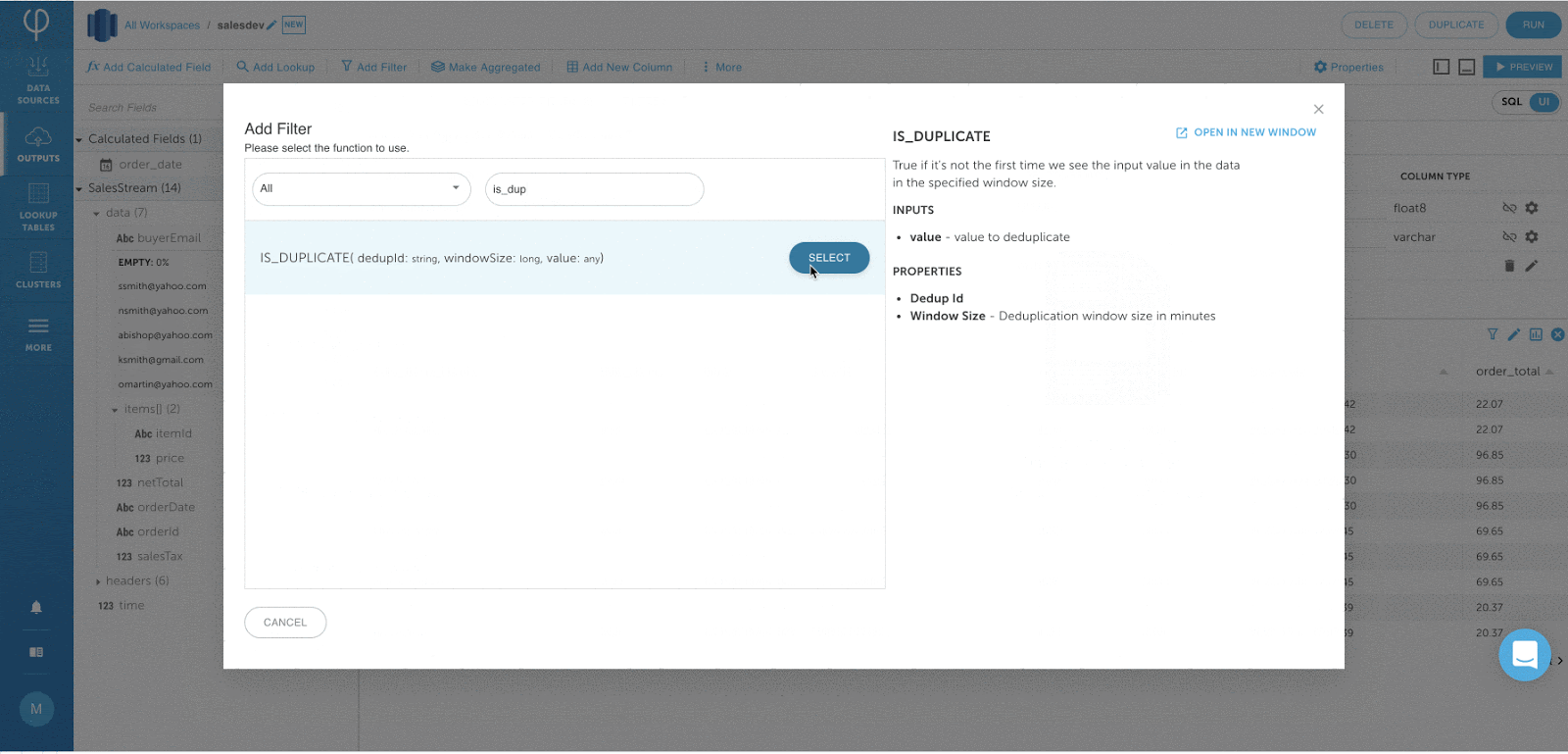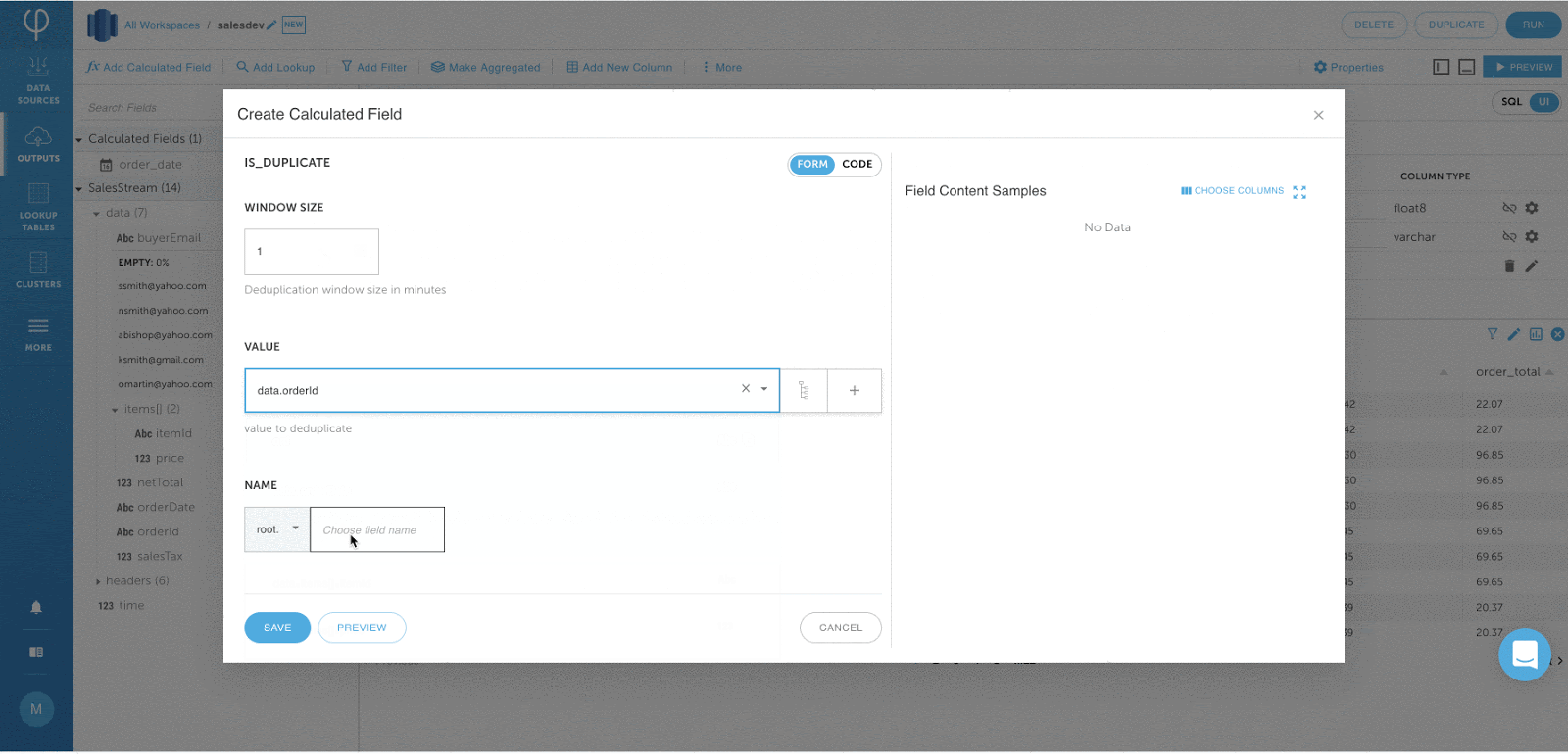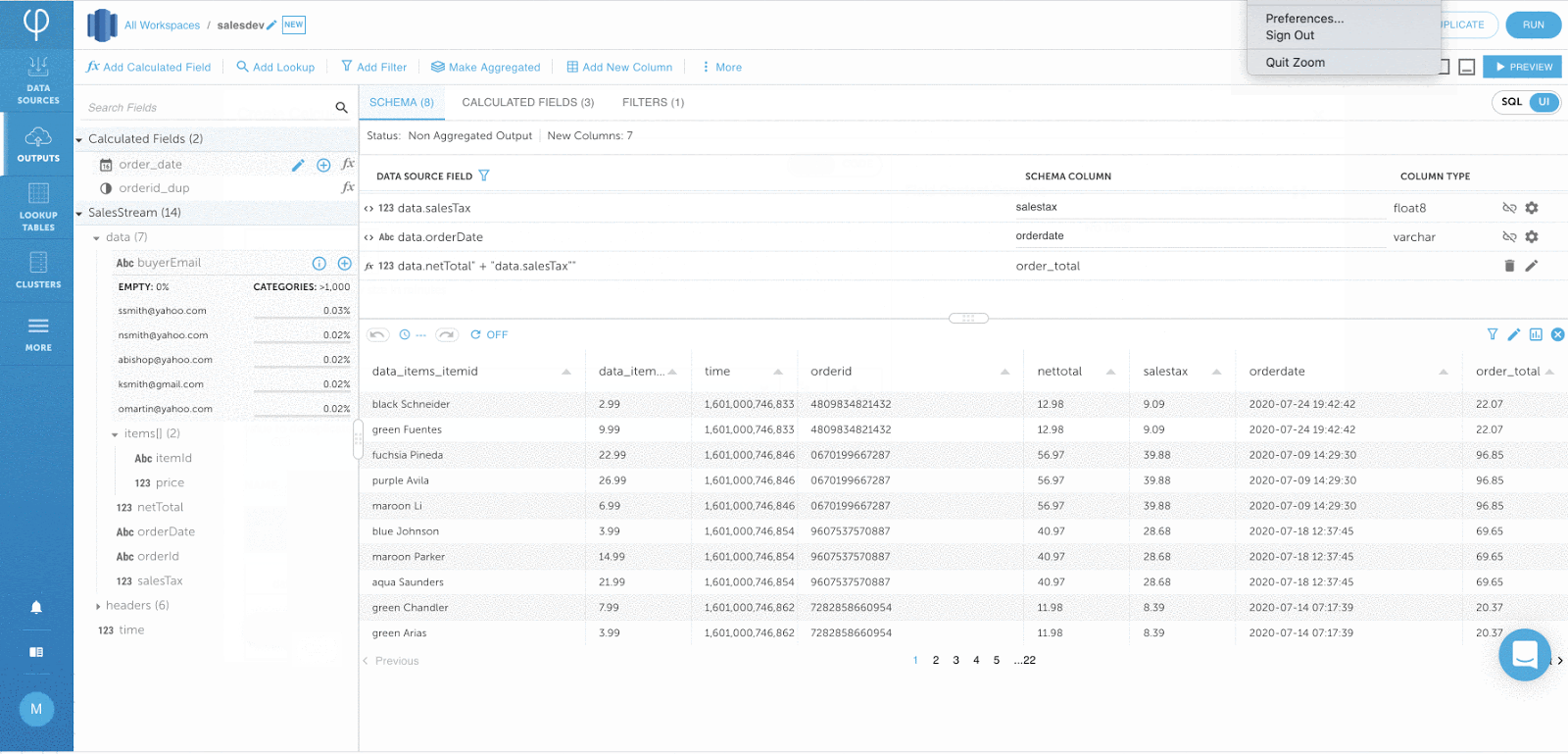
Definieren von Schlüsseln für Tabellen in Amazon Redshift:
Diese Funktion ist erforderlich, um Anwendungsfälle wie das Streaming von Änderungsdatenerfassungsprotokollen und die Durchsetzung der GDPR / CCPA-Konformität in Amazon Redshift zu unterstützen.
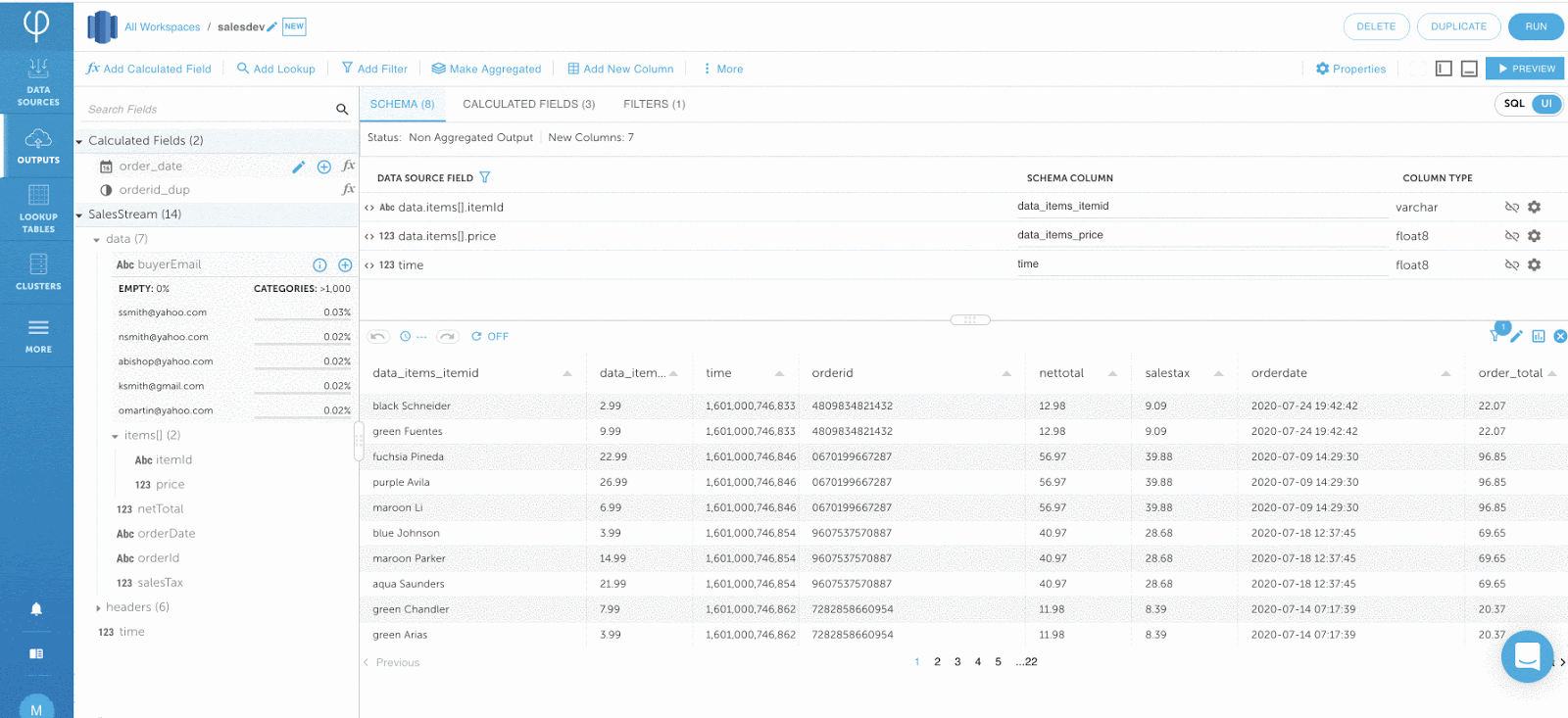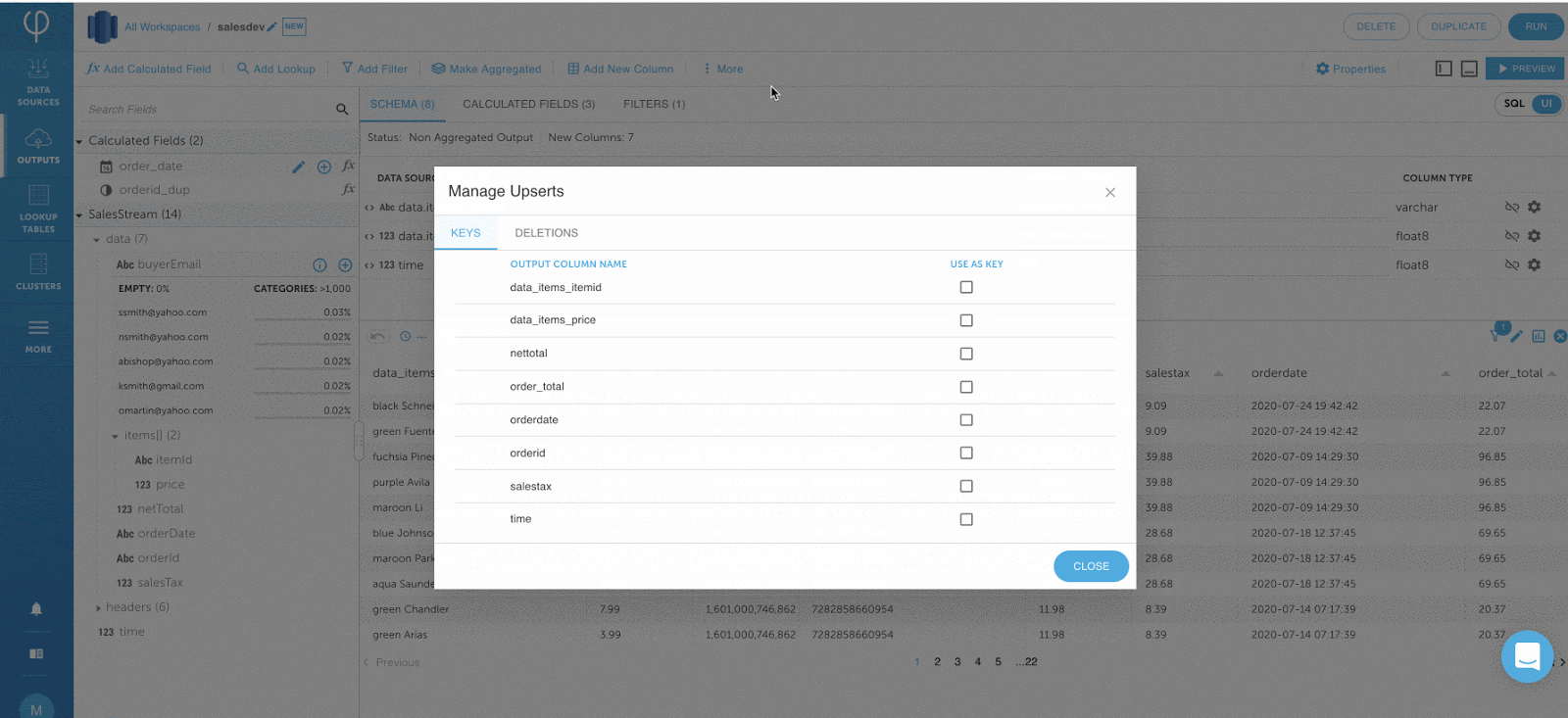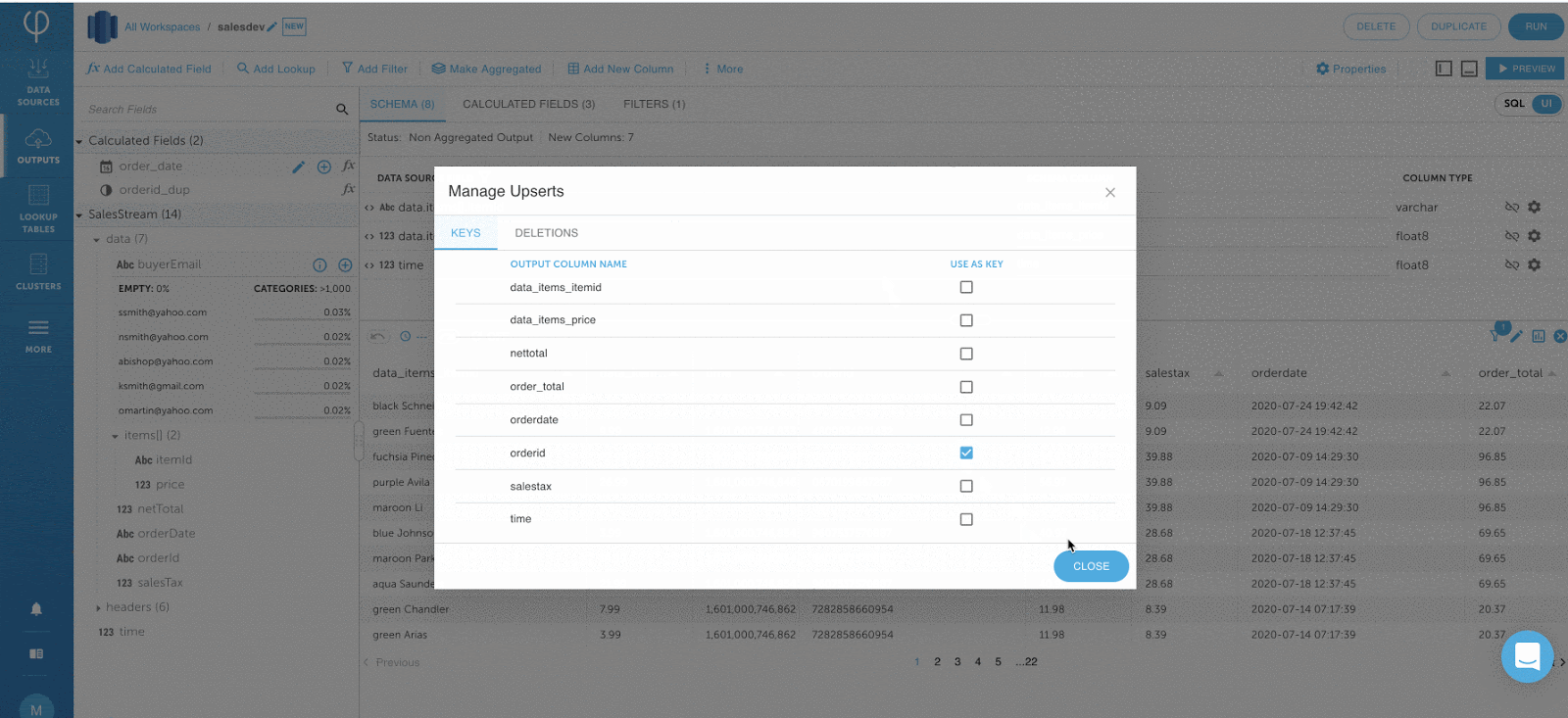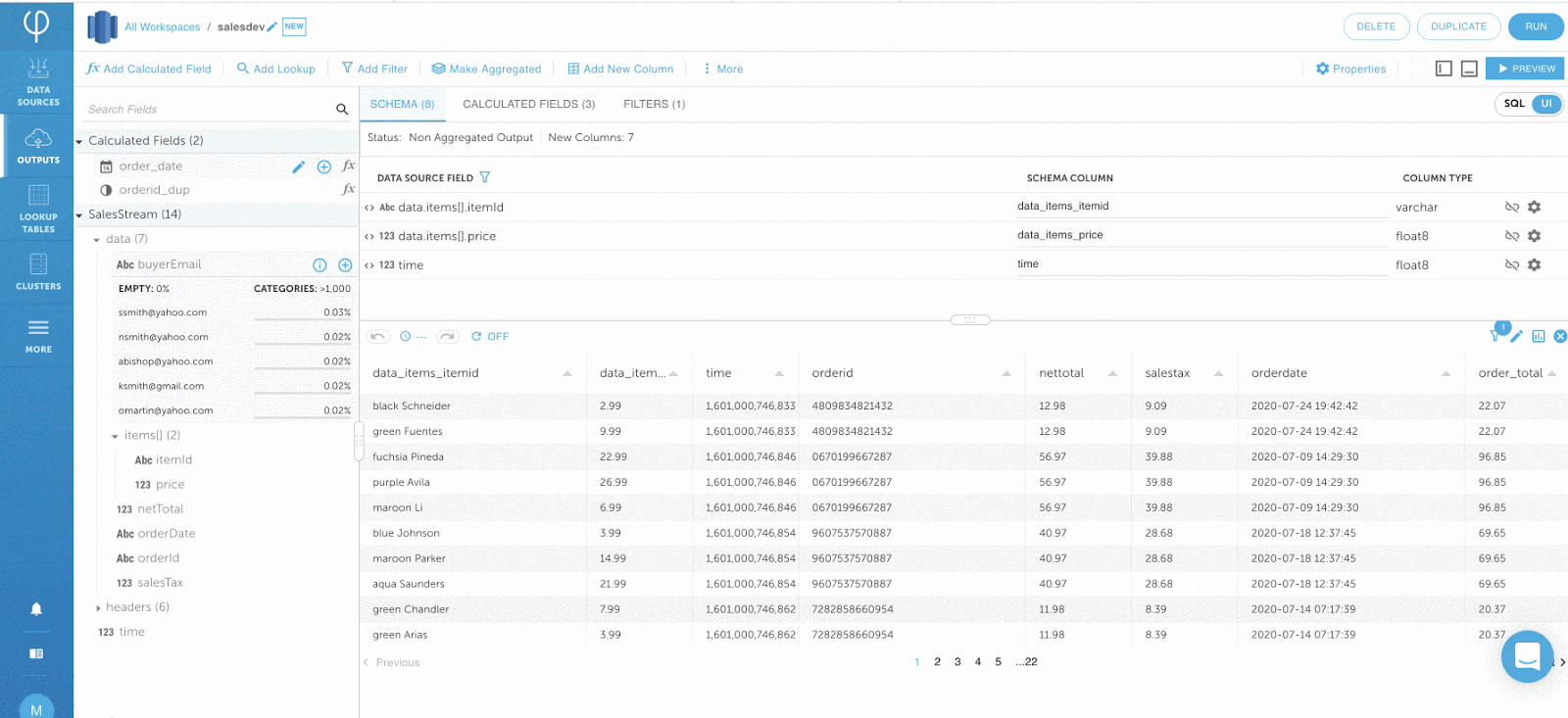
Schritt 3: Optimieren der Jobabfrage ausführen
Nachdem Ihre Ausgabe fertig ist, klicken Sie auf RUN, um Ihren Job auszuführen.
Geben Sie zunächst die Anmeldeinformationen für Redshift ein:

Zweitens Wählen Sie den Upsolver-Cluster für die Ausführung der Ausgabe und den Zeitrahmen für die Ausführung.
Upsolver-Cluster werden auf Amazon EC2-Spotinstanzen ausgeführt und basierend auf der Rechenauslastung automatisch skaliert.
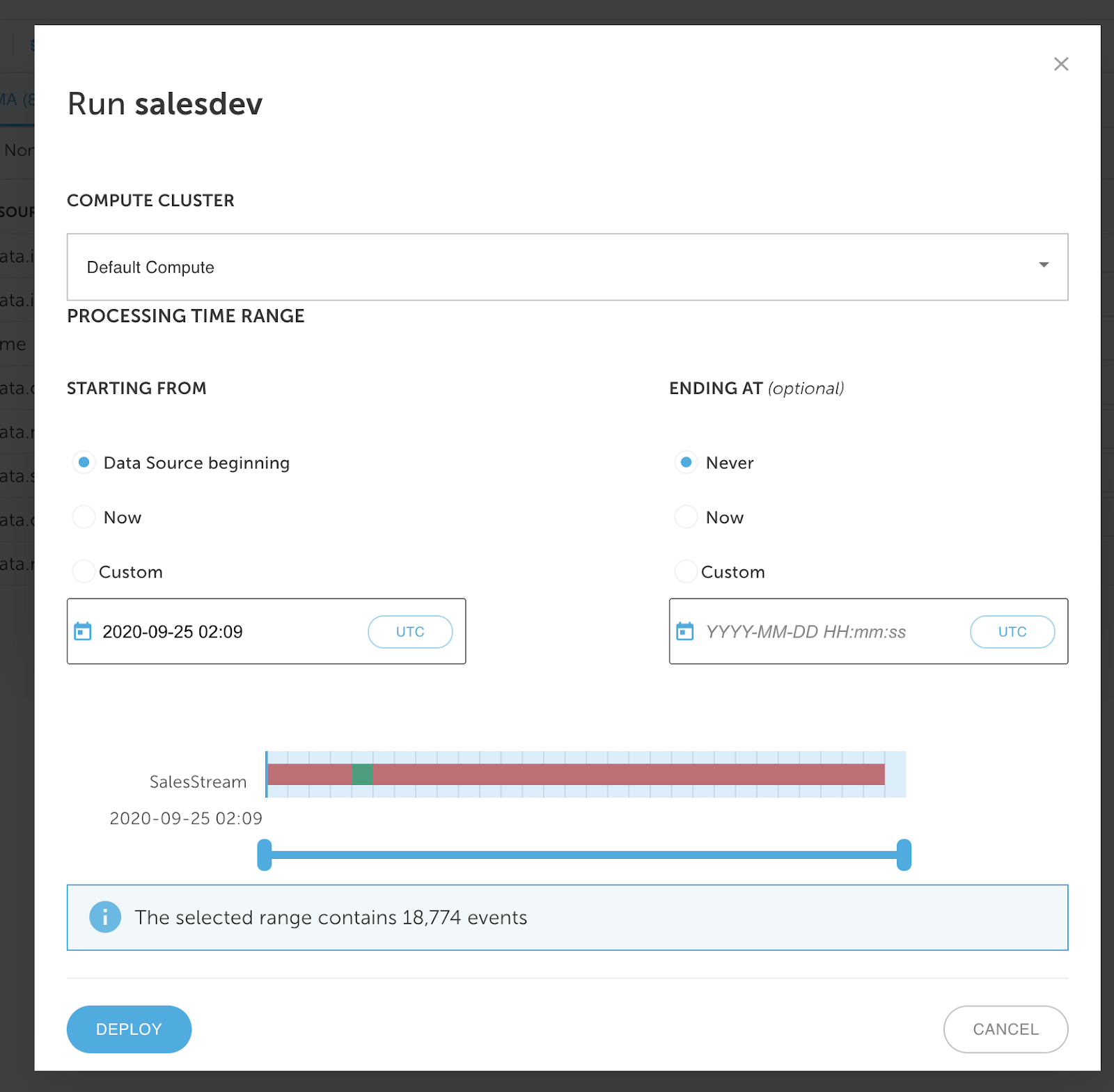
Beachten Sie, dass der Benutzer während des gesamten Vorgangs nur Datentransformationen definieren musste: Der Verarbeitungsjob wird automatisch orchestriert, und die Engine garantiert genau die einmalige Datenkonsistenz. Die Implementierung dieser Best Practices führt zu schnelleren Abfragen, die Redshift und Dashboards in Sisense unterstützen.
Schritt 4: Abfrage
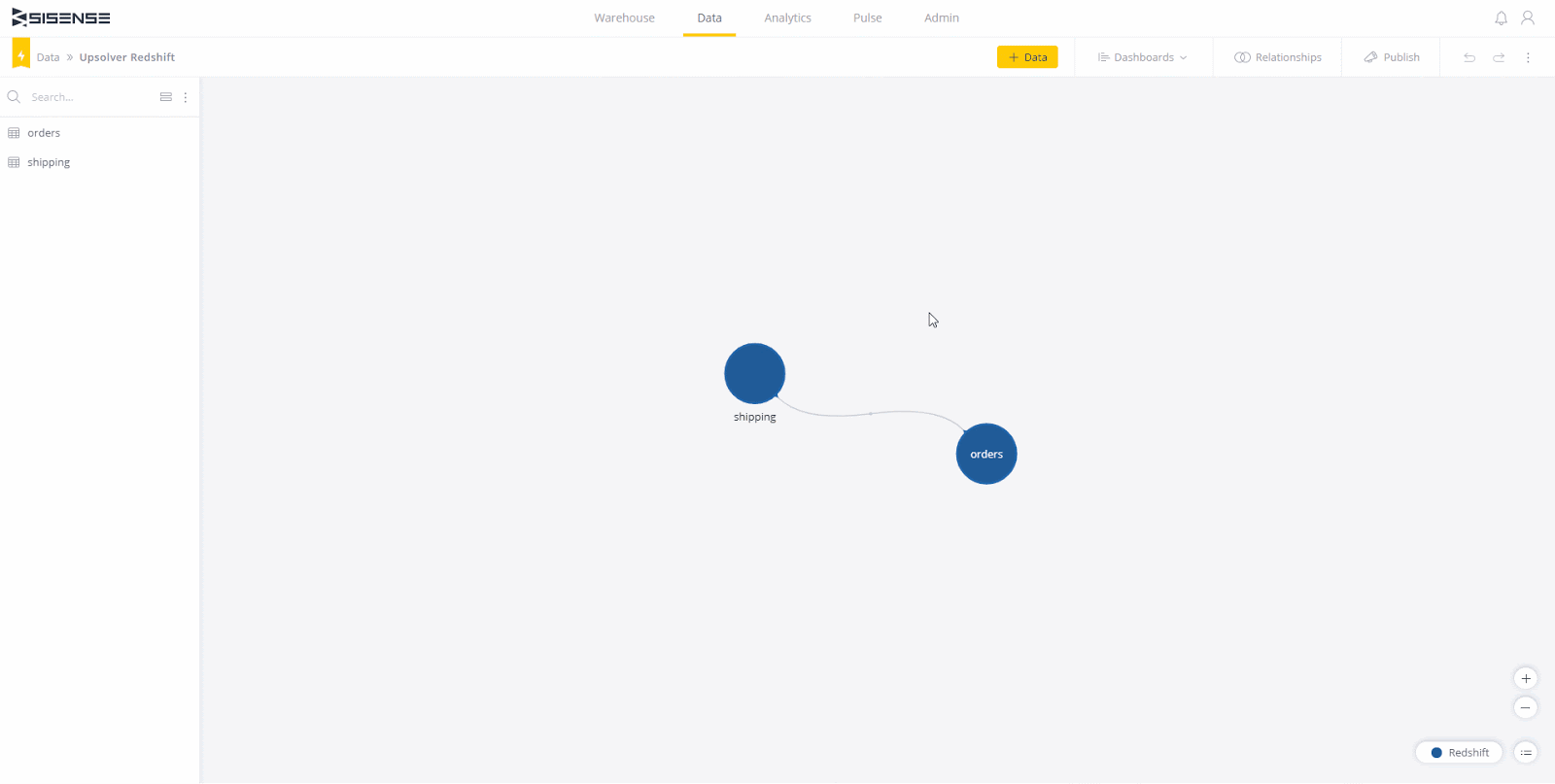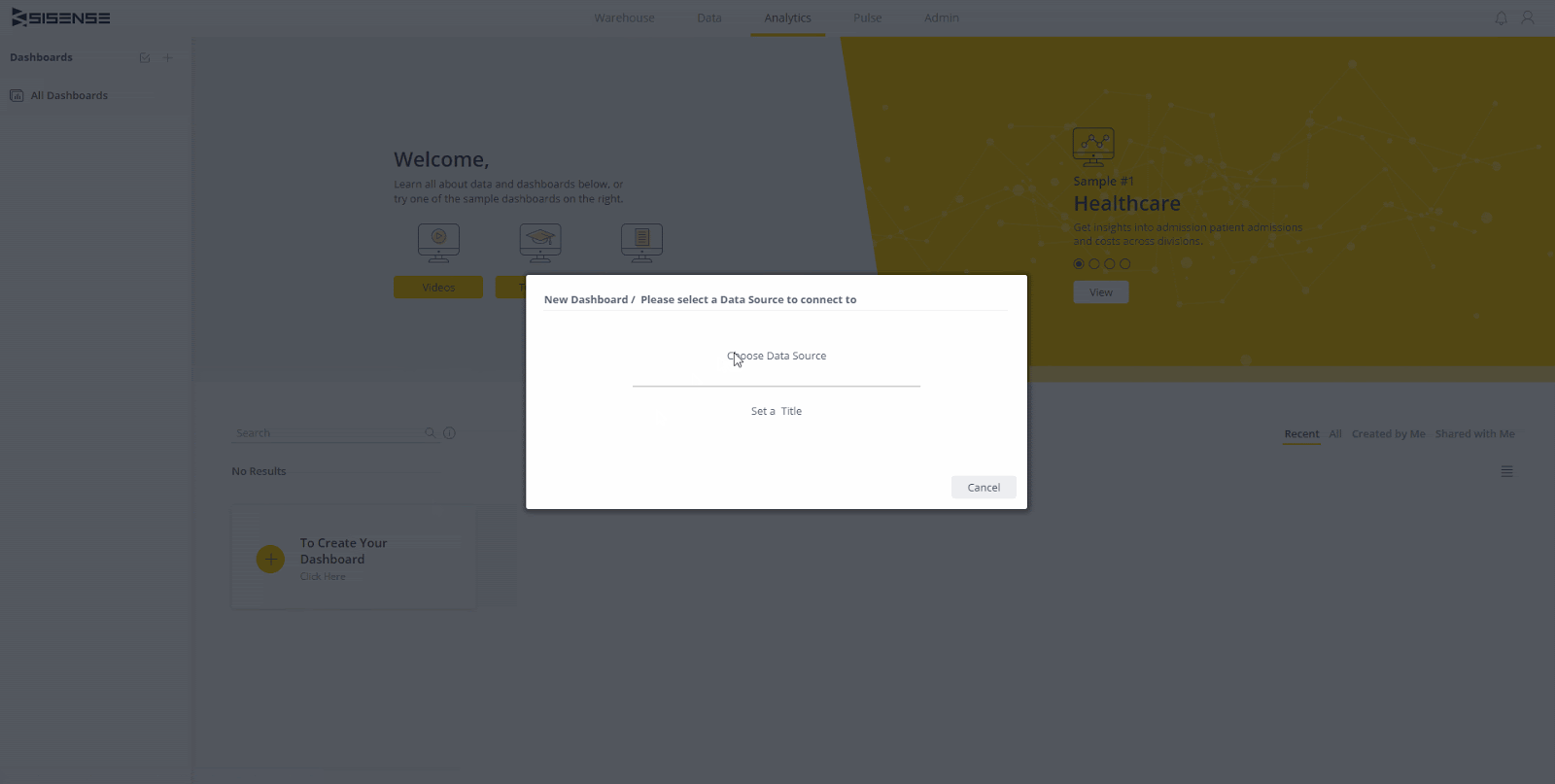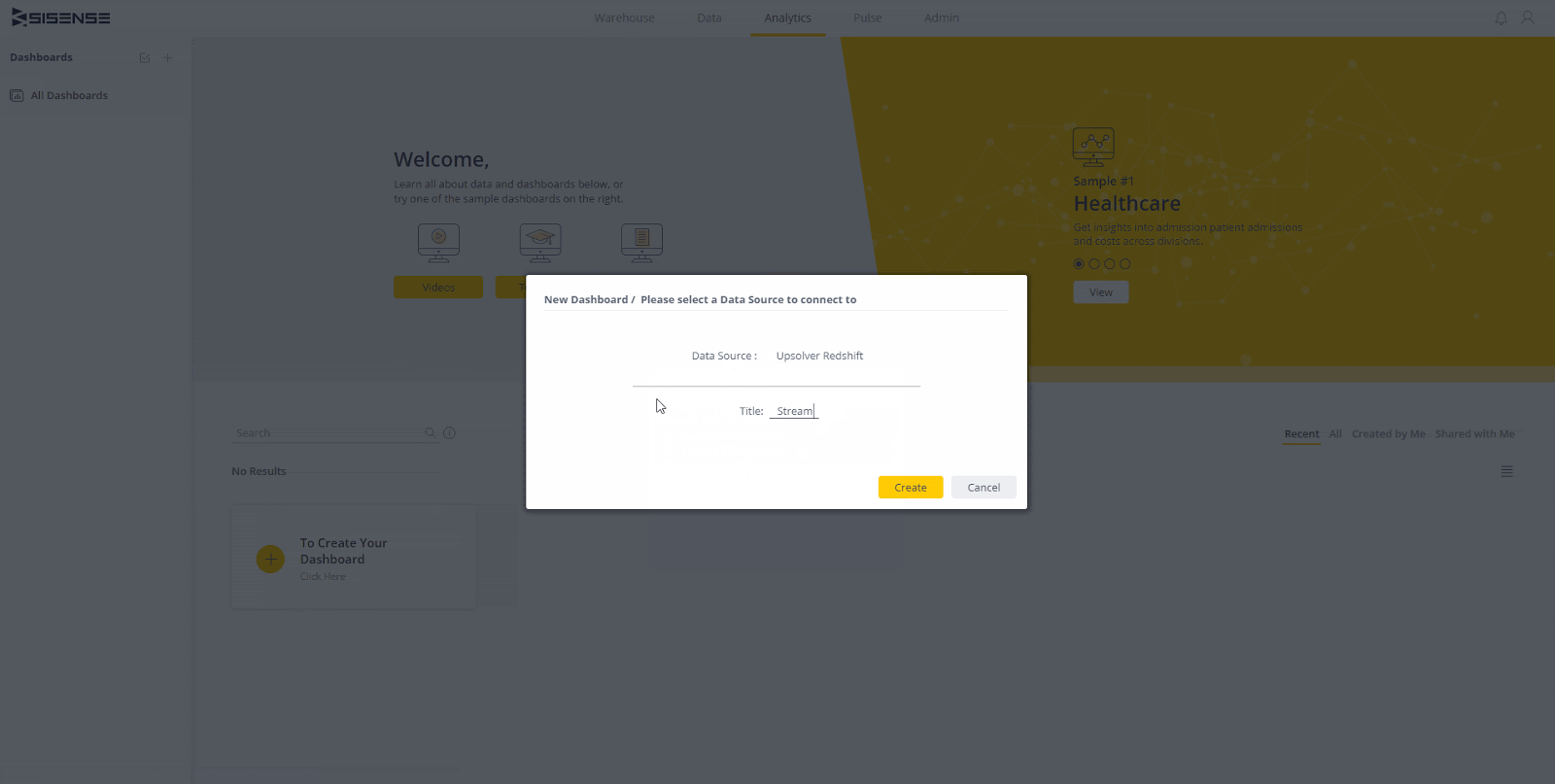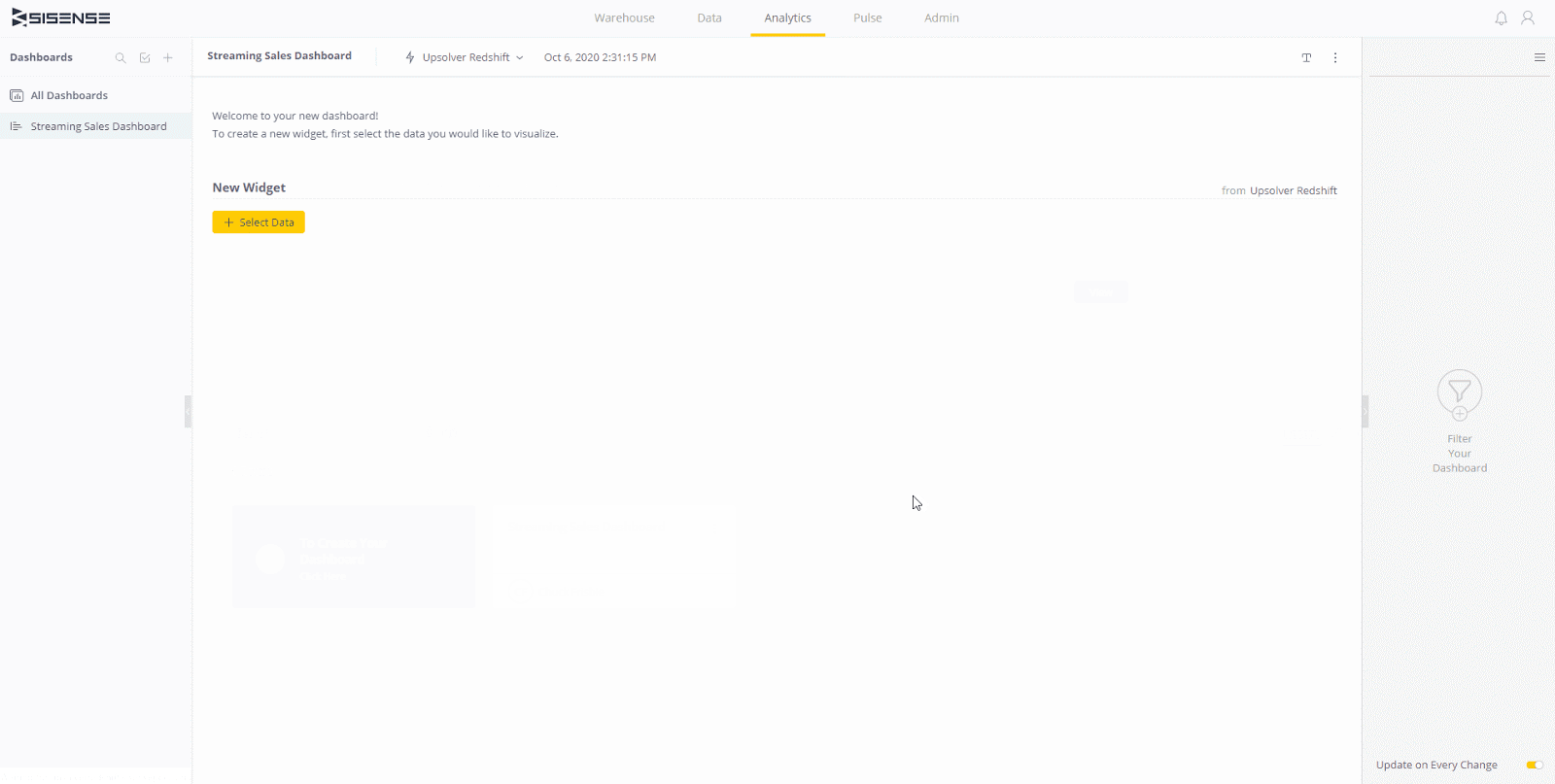
Melden Sie sich mit mindestens Data Designer-Berechtigungen bei Ihrer Sisense-Umgebung an. Wir werden eine Live-Verbindung zum in Schritt 3 eingerichteten Redshift-Cluster und ein einfaches Dashboard herstellen. Der erste Schritt besteht darin, zur Registerkarte „Daten“ zu navigieren und ein neues Live-Modell zu erstellen. Sie können ihm einen beliebigen Namen geben.
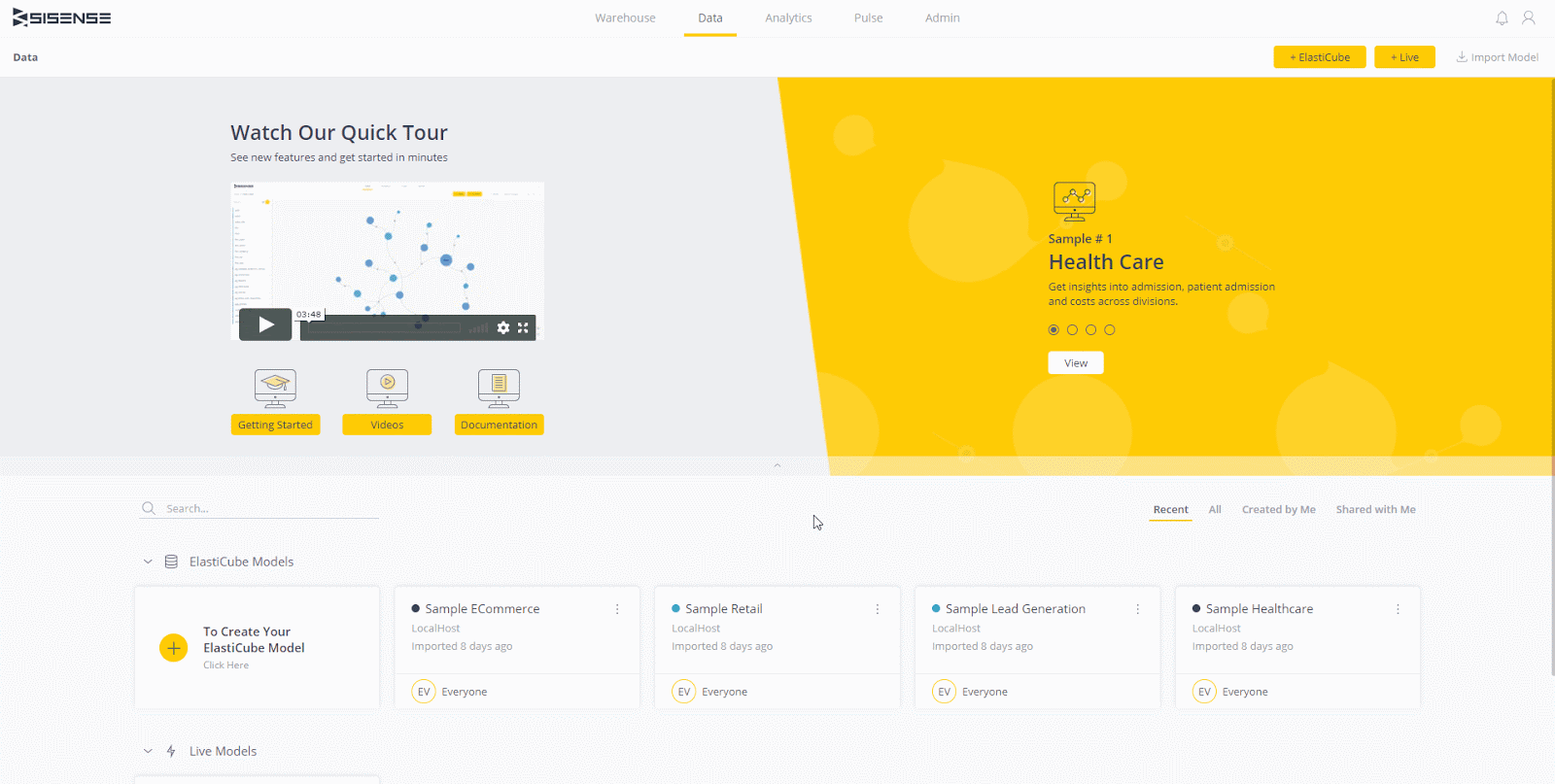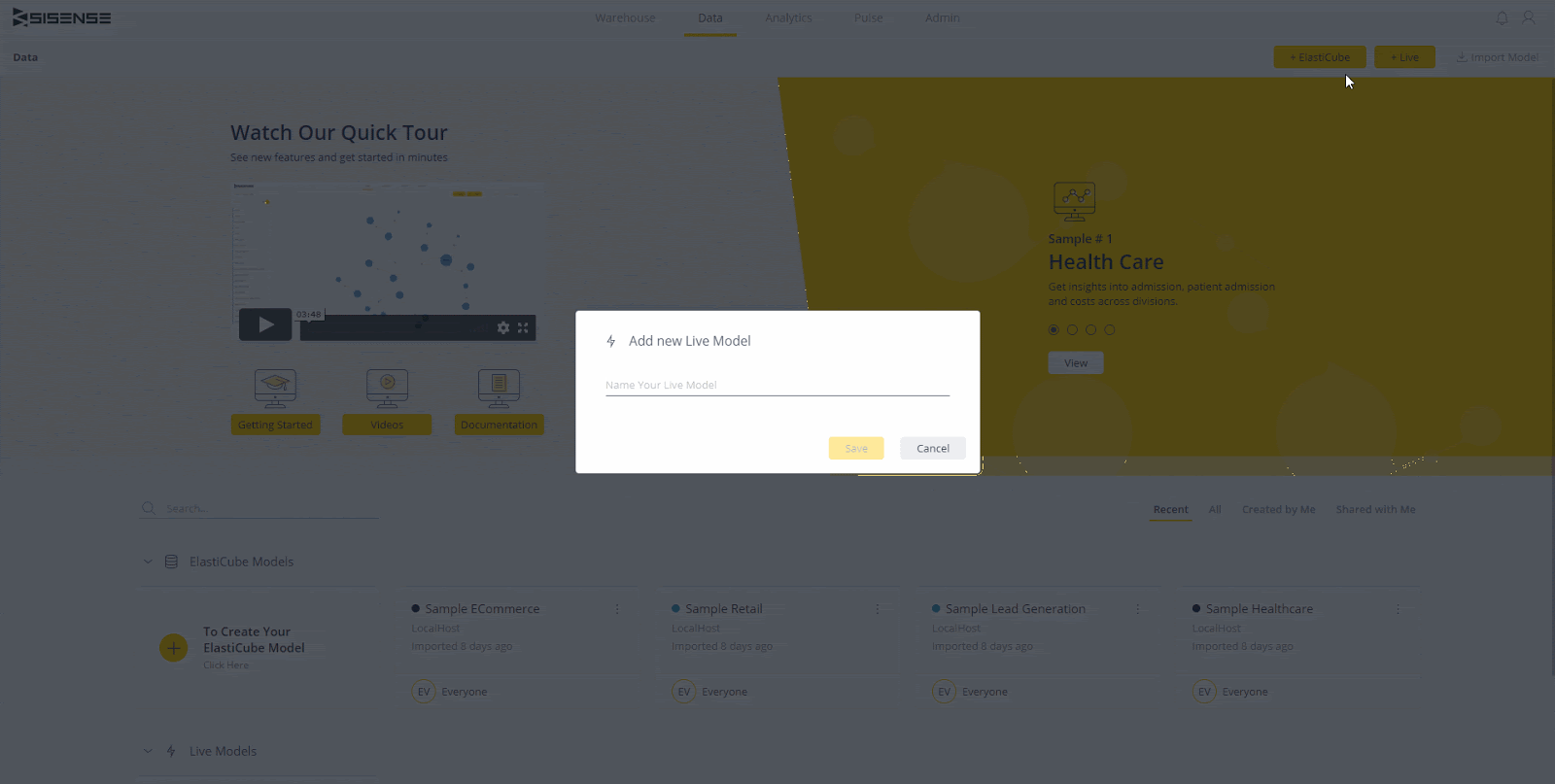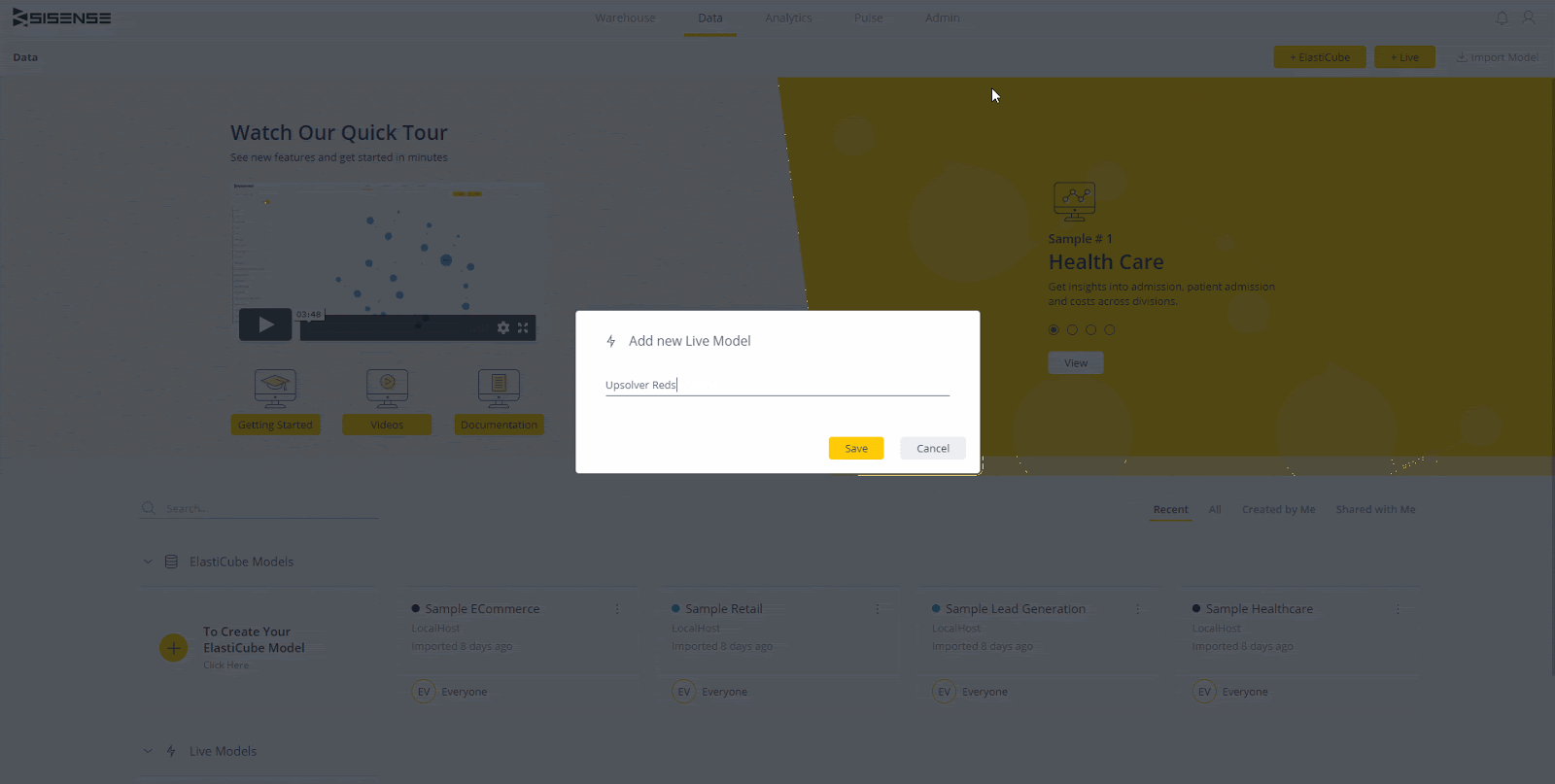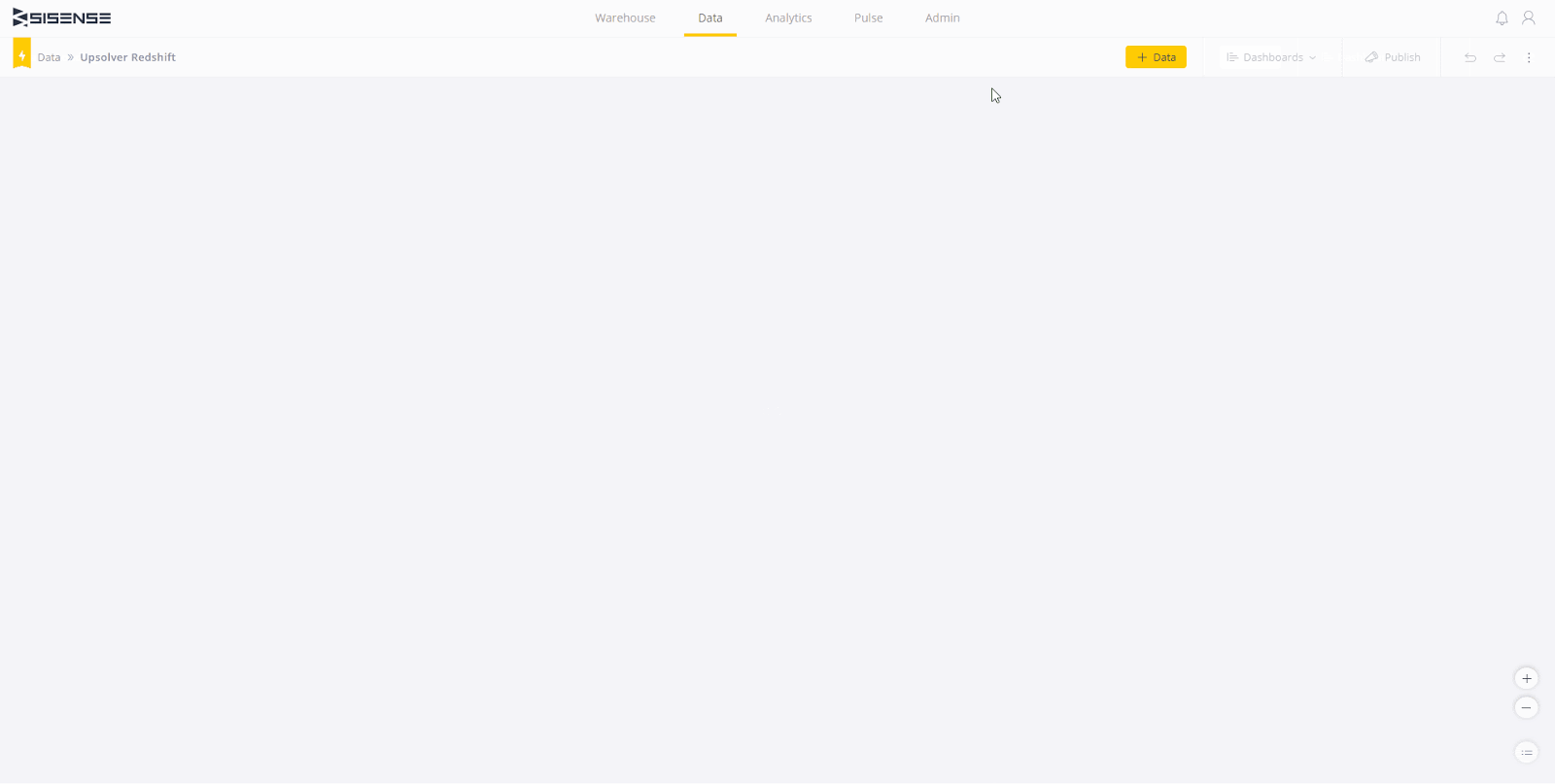
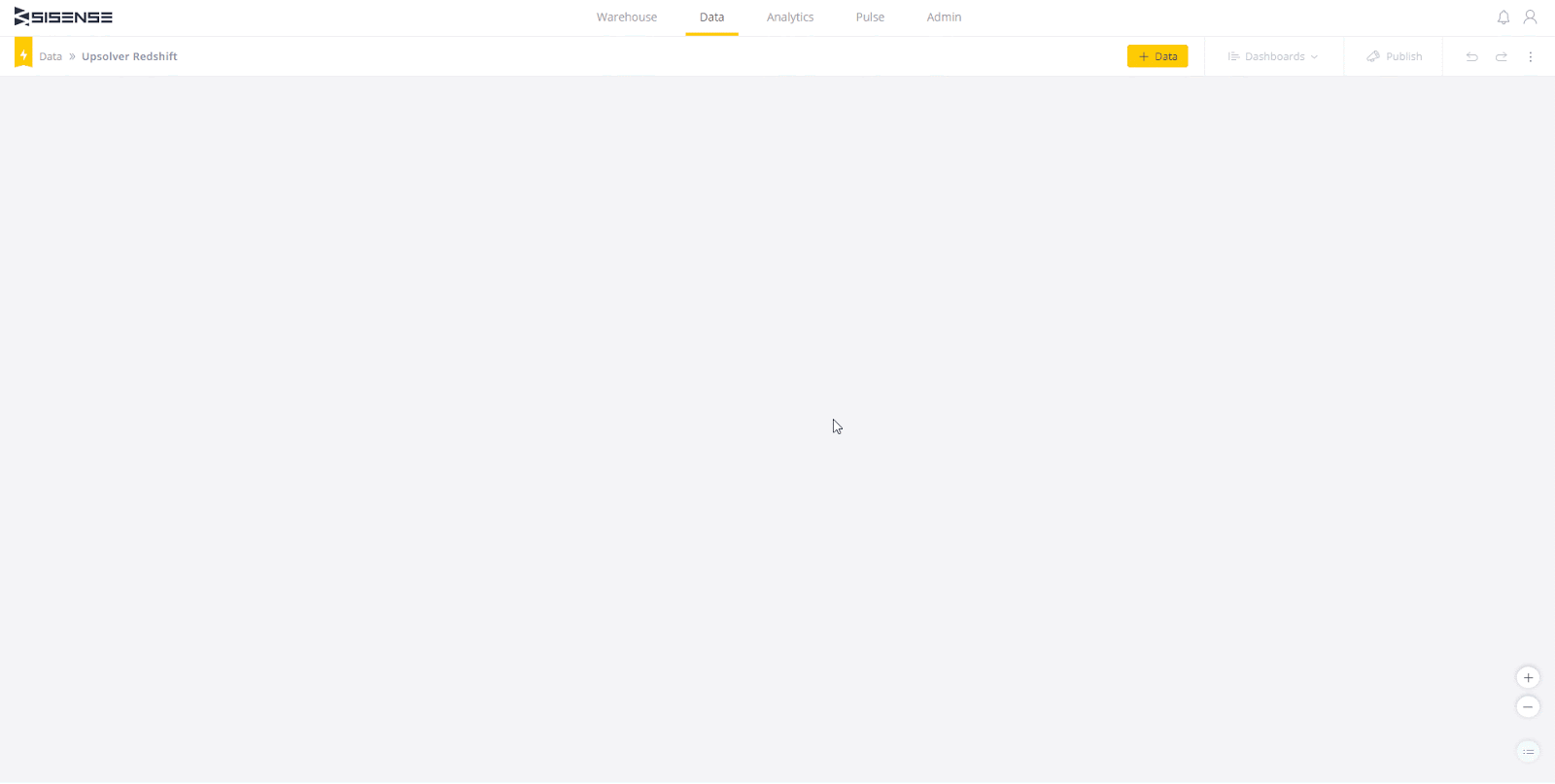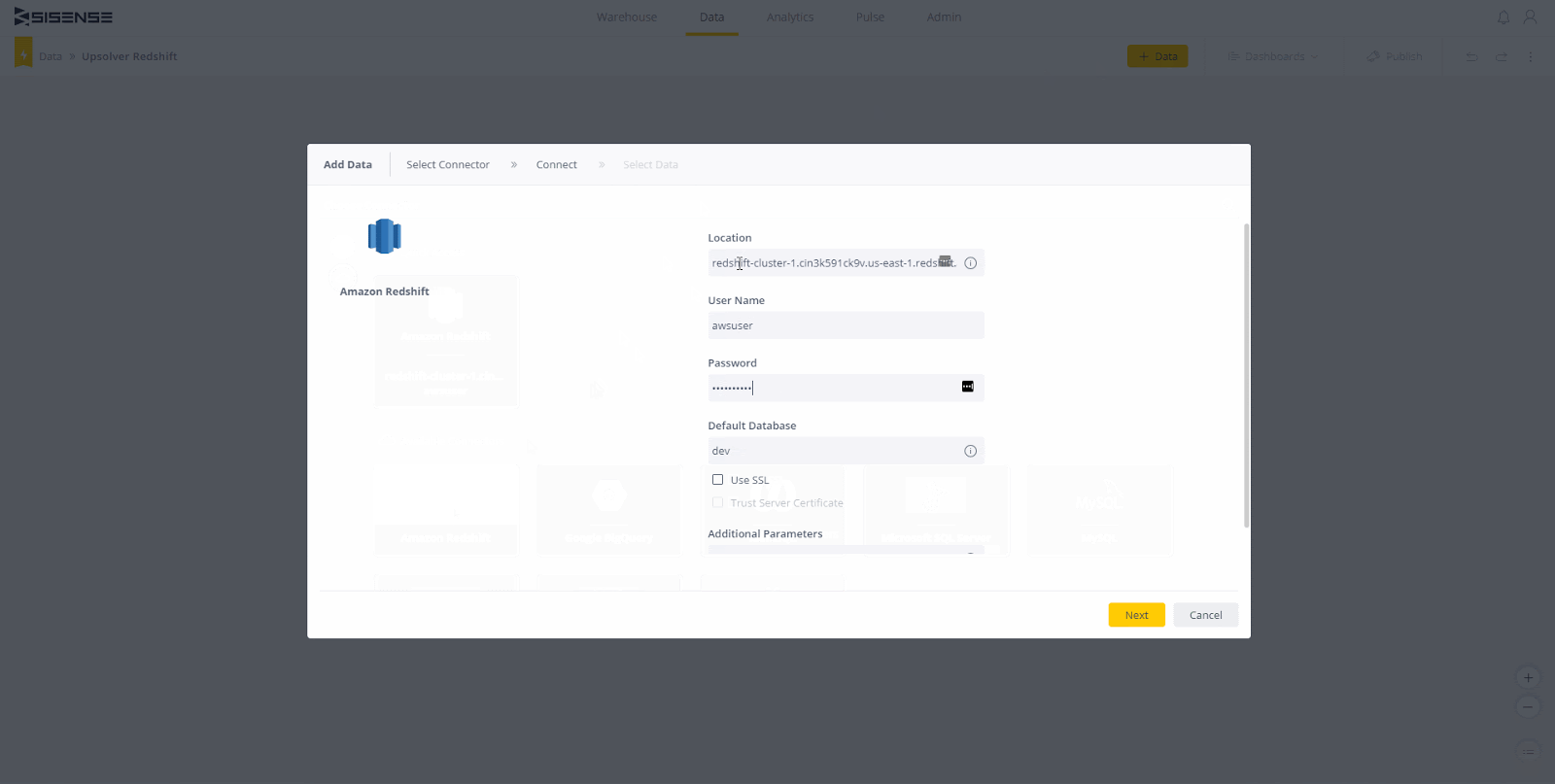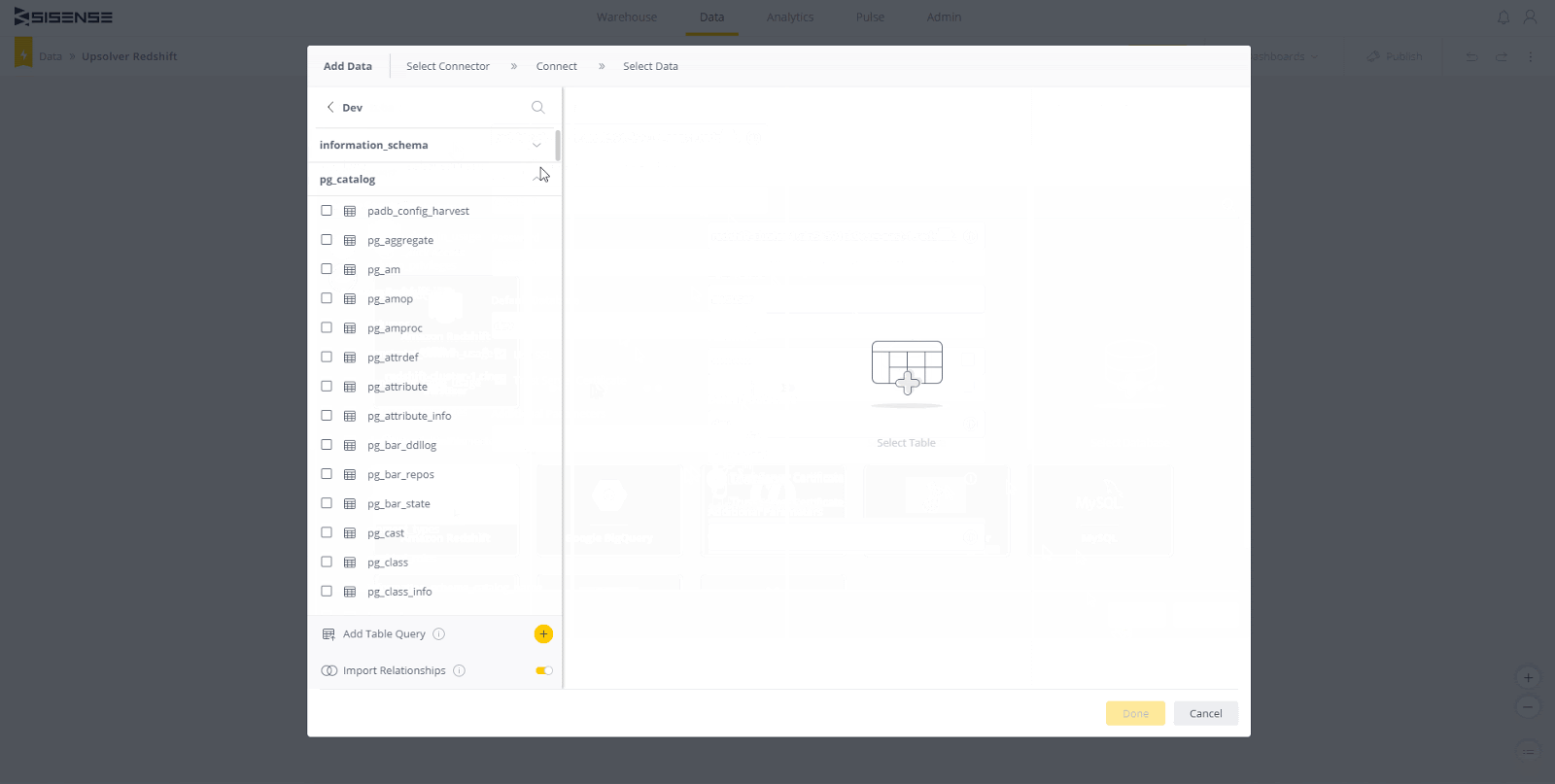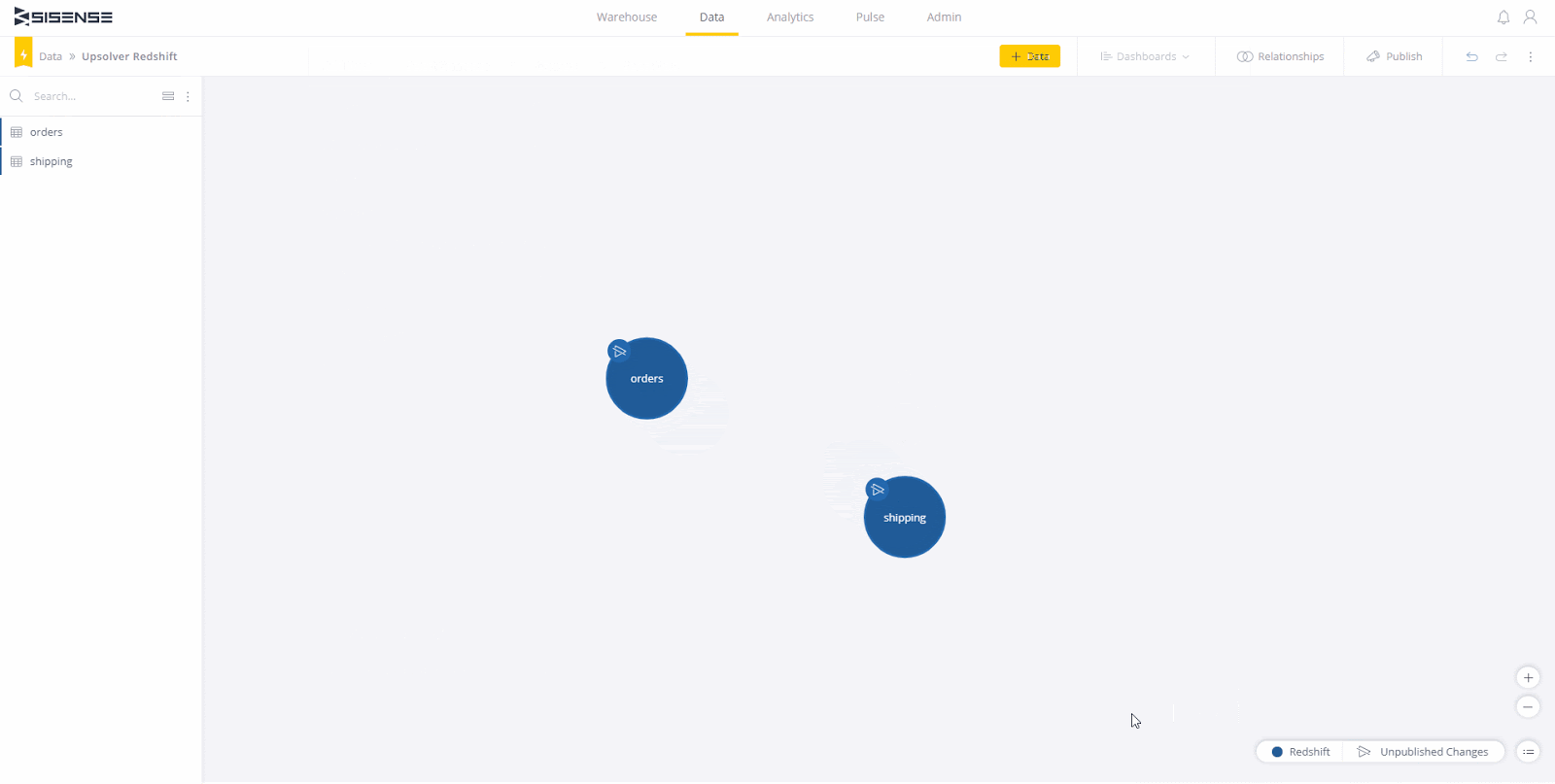
Stellen Sie nun eine Verbindung zu Redshift her. Klicken Sie oben rechts auf dem Bildschirm auf die Schaltfläche „+ Daten“. Wählen Sie Rotverschiebung aus der Liste der verfügbaren Verbindungen. Als Nächstes müssen Sie Ihren Redshift-Standort und Ihre Anmeldeinformationen eingeben. Der Speicherort ist die URL / der Endpunkt für den Cluster. Die verwendeten Anmeldeinformationen sollten Lesezugriff auf die von Ihnen verwendeten Daten haben. Stellen Sie sicher, dass "SSL verwenden" und "Trust Server-Zertifikat verwenden" aktiviert sind (die meisten Cluster erfordern diese Optionen standardmäßig).
Wenn Sie fertig sind, klicken Sie auf "Weiter" und wählen Sie die Datenbank aus, zu der Sie eine Verbindung herstellen möchten. Klicken Sie dann erneut auf "Weiter".
Hier sehen Sie alle Tabellen, auf die Sie Zugriff haben, getrennt nach Schema. Navigieren Sie zu dem Schema / den Tabellen, die Sie importieren möchten, und wählen Sie zunächst einige aus. Sie können später jederzeit mehr hinzufügen. Wenn Sie fertig sind, klicken Sie auf "Fertig", um diese Tabellen zu Ihrem Modell hinzuzufügen.
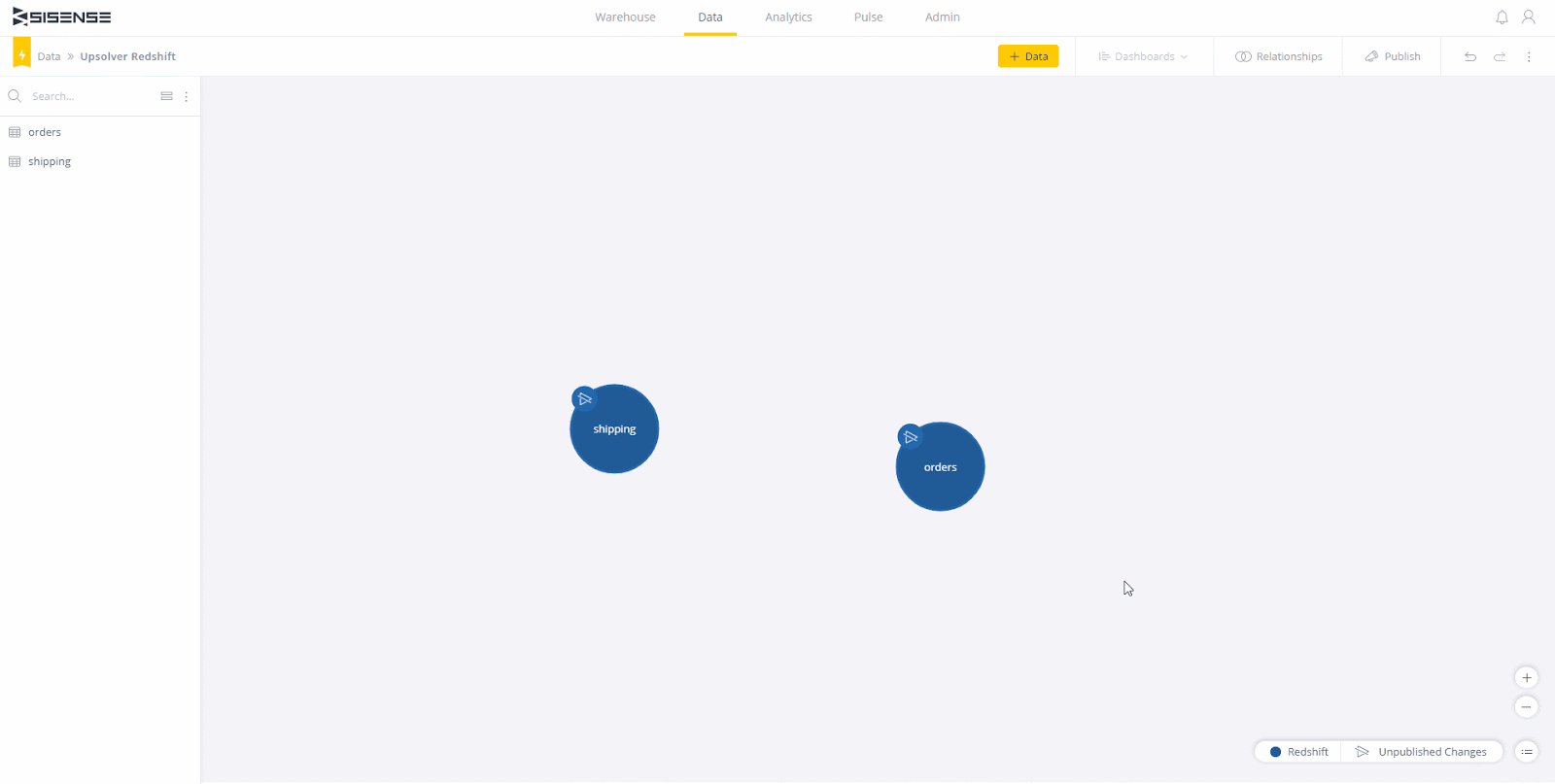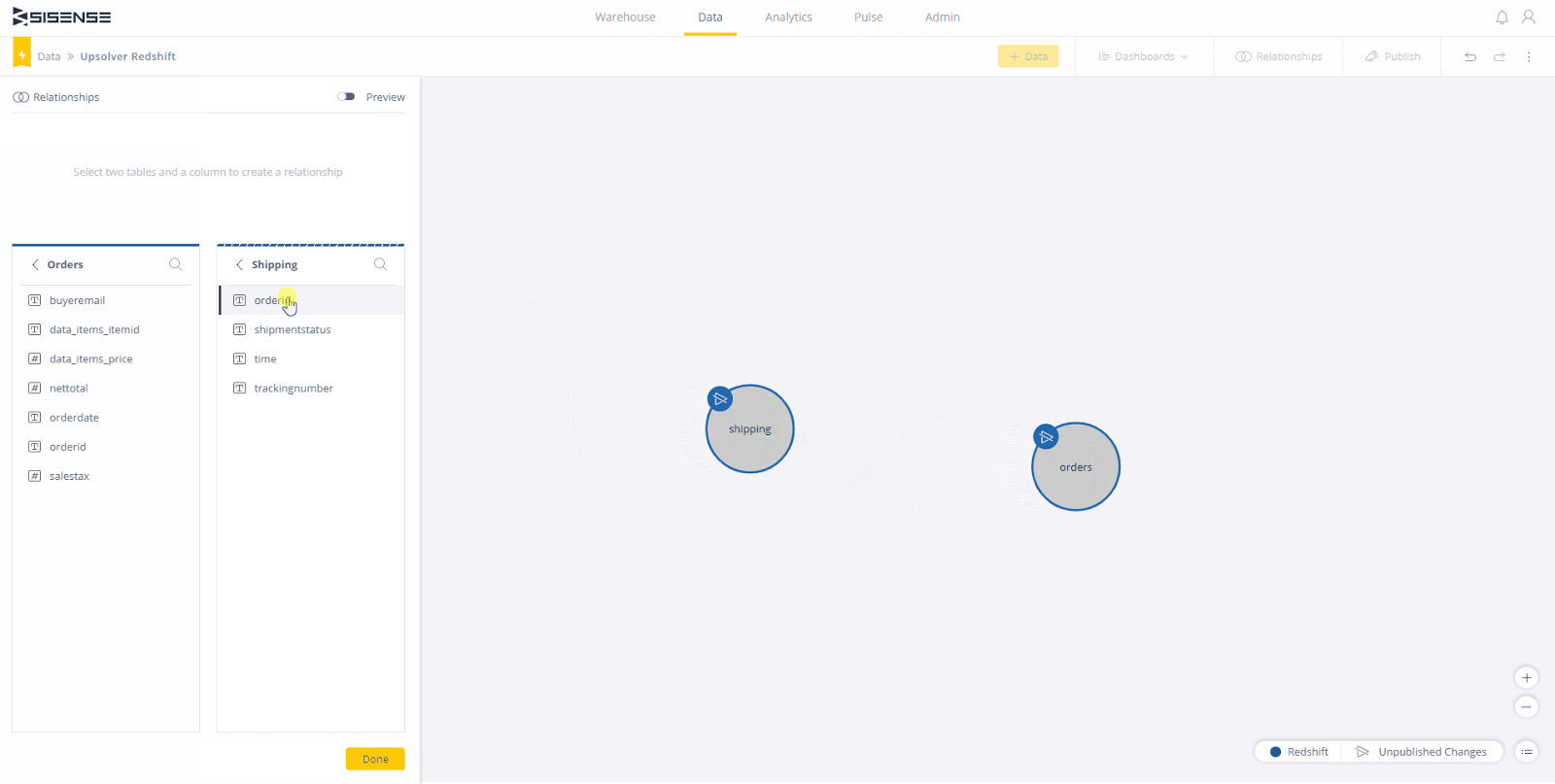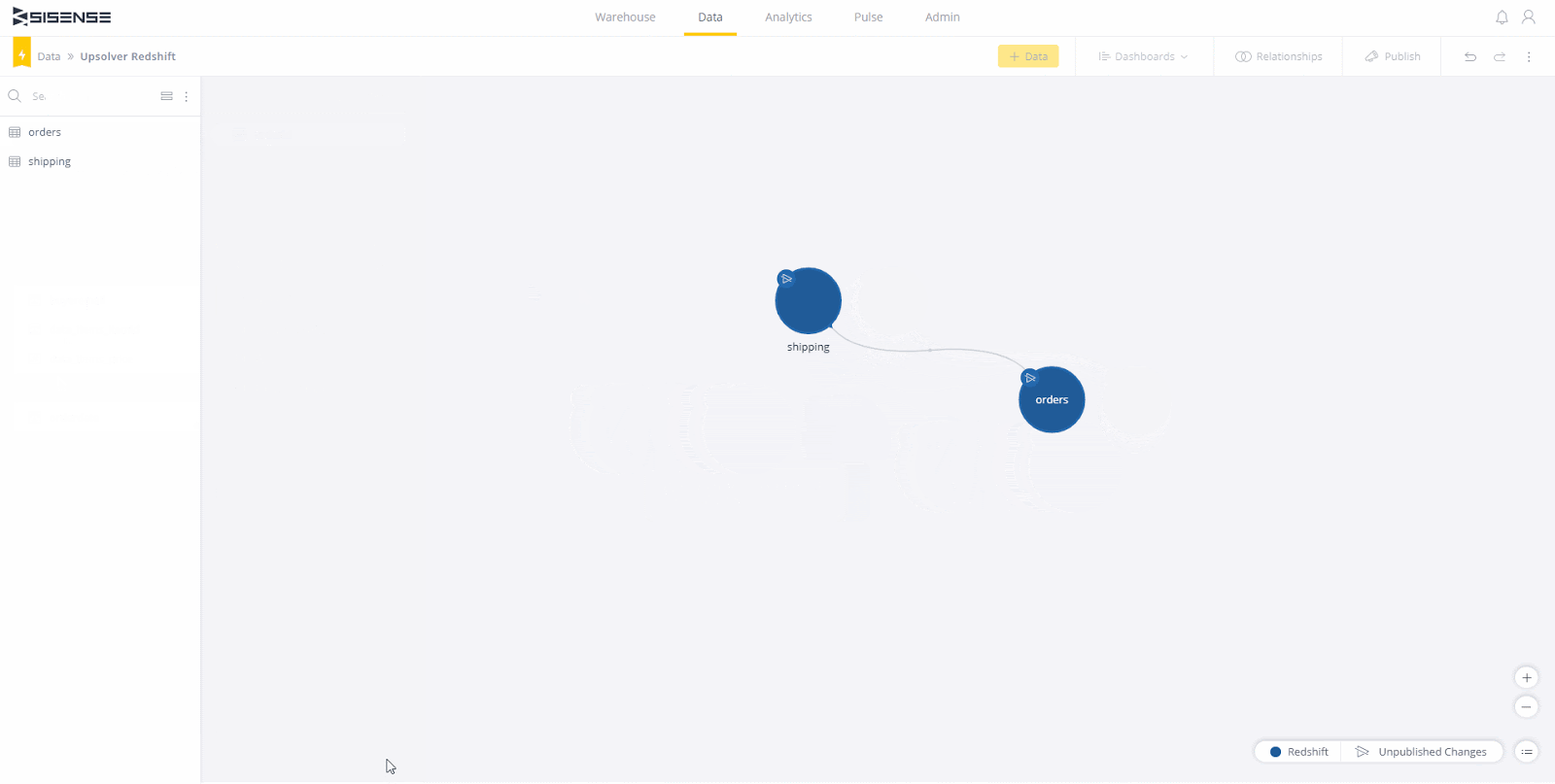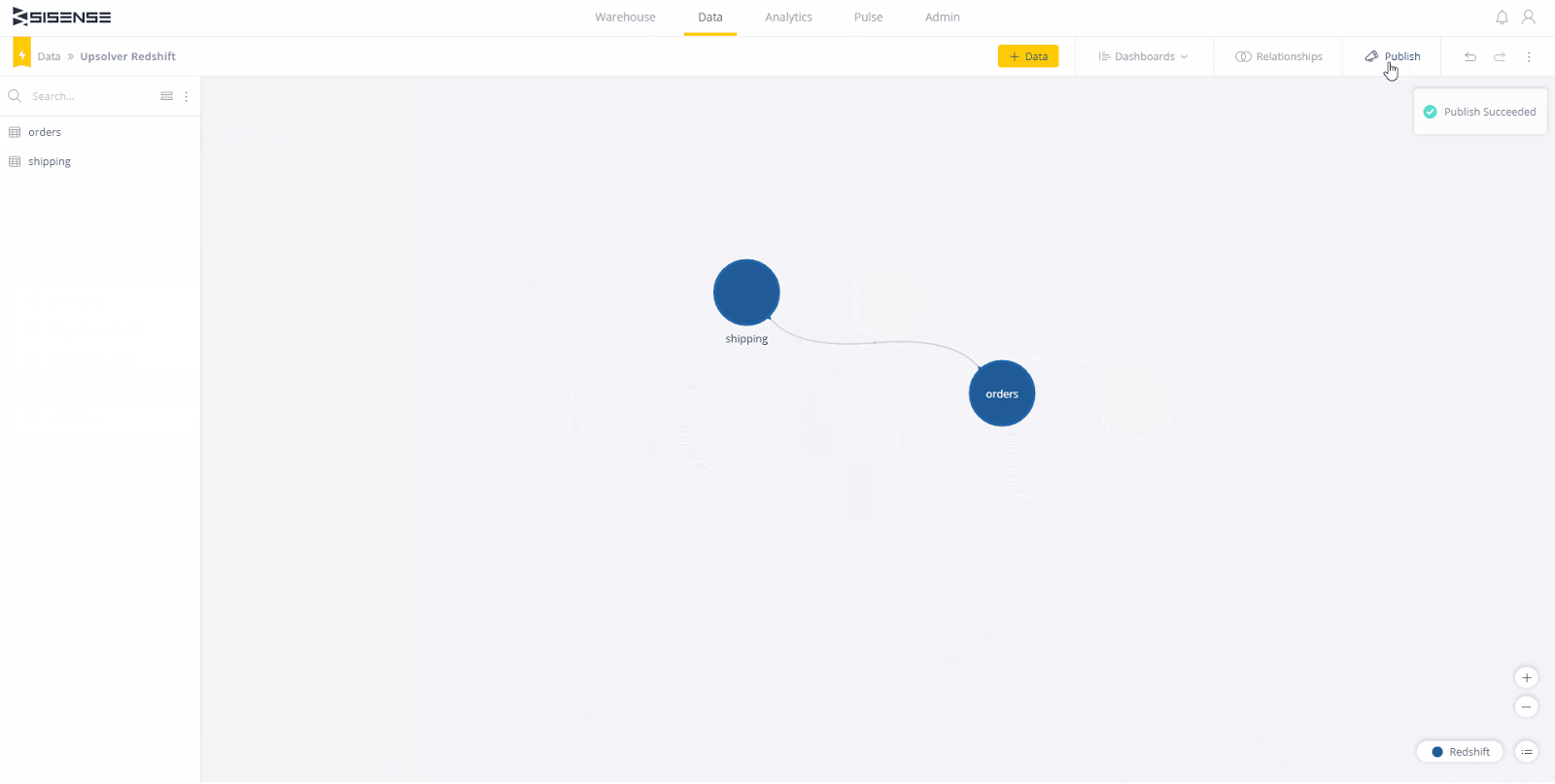
Sobald Sie Tabellen zum Arbeiten haben, ist es Zeit, sie zu verbinden. In diesem Fall verlinken die Tabellen auf "orderId". Ziehen Sie einfach eine Tabelle auf die andere und wählen Sie das Verknüpfungsfeld (den Schlüssel) auf beiden Seiten aus. Wenn die Linie zwischen den Tabellen angezeigt wird, können Sie auf "Fertig" klicken. Klicken Sie abschließend oben rechts auf "Veröffentlichen" und Sie können ein Dashboard erstellen!
Nun müssen Sie zur Registerkarte "Analytics" navigieren. Hier erstellen wir ein neues Dashboard, um die Daten anzuzeigen und zu untersuchen. Dort sehen Sie eine Schaltfläche zum Erstellen eines neuen Dashboards. Klicken Sie darauf und wählen Sie das gerade veröffentlichte Live-Modell aus. Sie können dem Dashboard einen anderen Namen geben, oder es wird standardmäßig derselbe Name wie das Modell verwendet.
Jetzt ist es an der Zeit, das Dashboard zu erstellen und Ihre Daten zu untersuchen. In der folgenden Animation erstellen wir einige verschiedene Visualisierungen basierend auf Feldern aus beiden Tabellen. Beachten Sie, dass wir Felder auswählen, die sowohl als Dimensionen als auch als Kennzahlen aus beiden Tabellen im Modell verwendet werden sollen. Sisense verbindet die Tabellen automatisch für uns und Upsolver hält die Daten in beiden Tabellen mit dem Stream synchron.
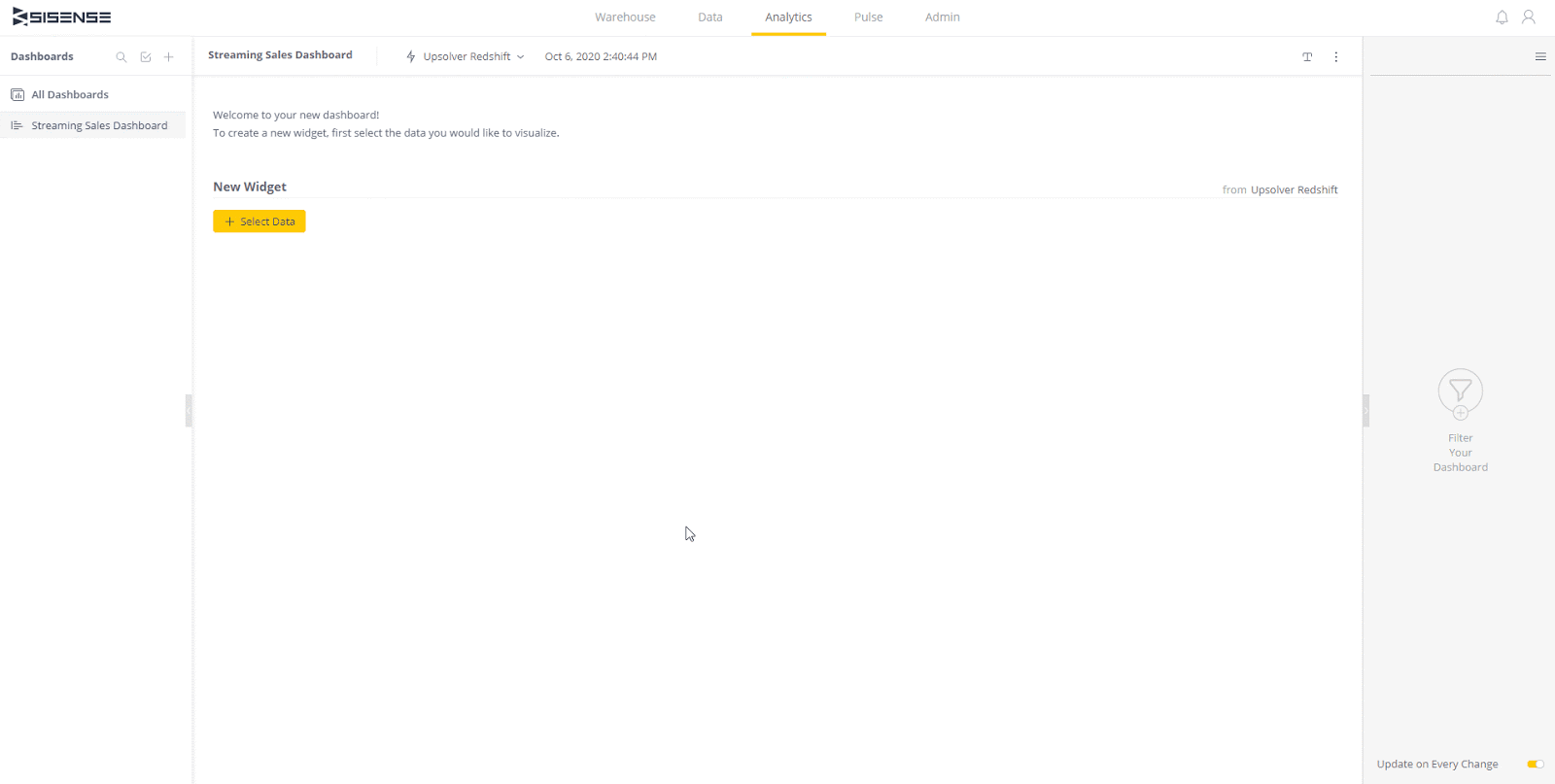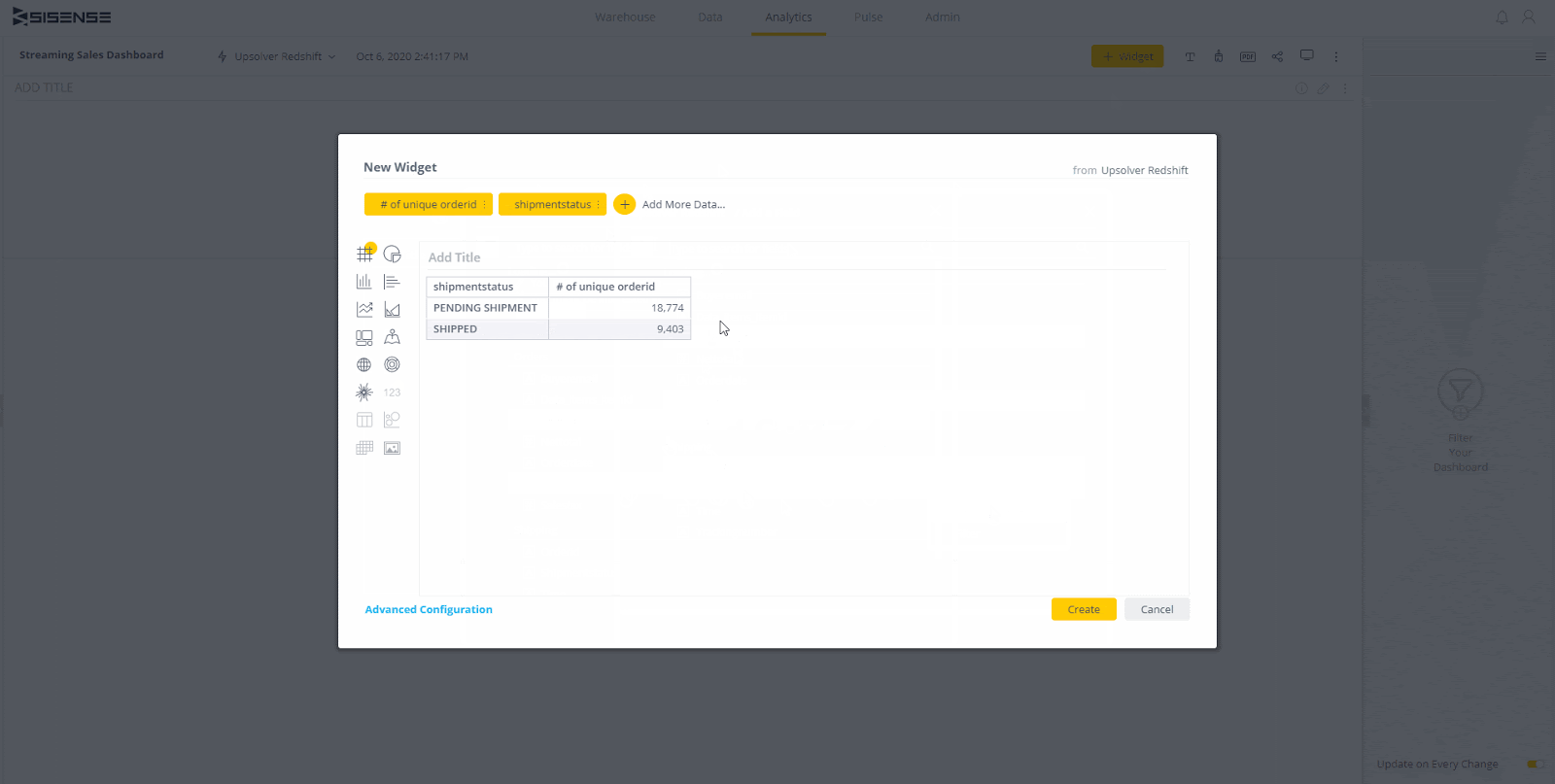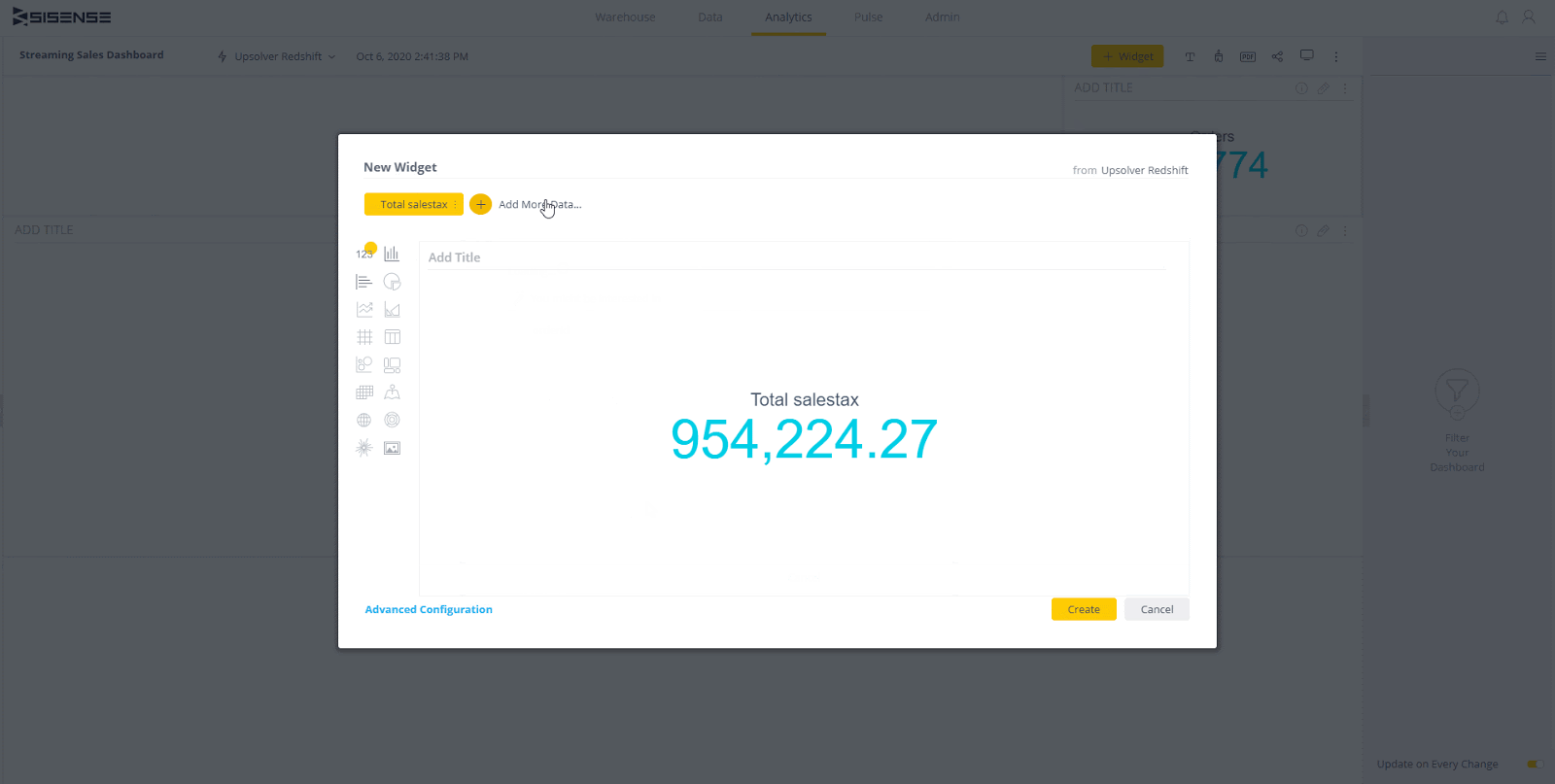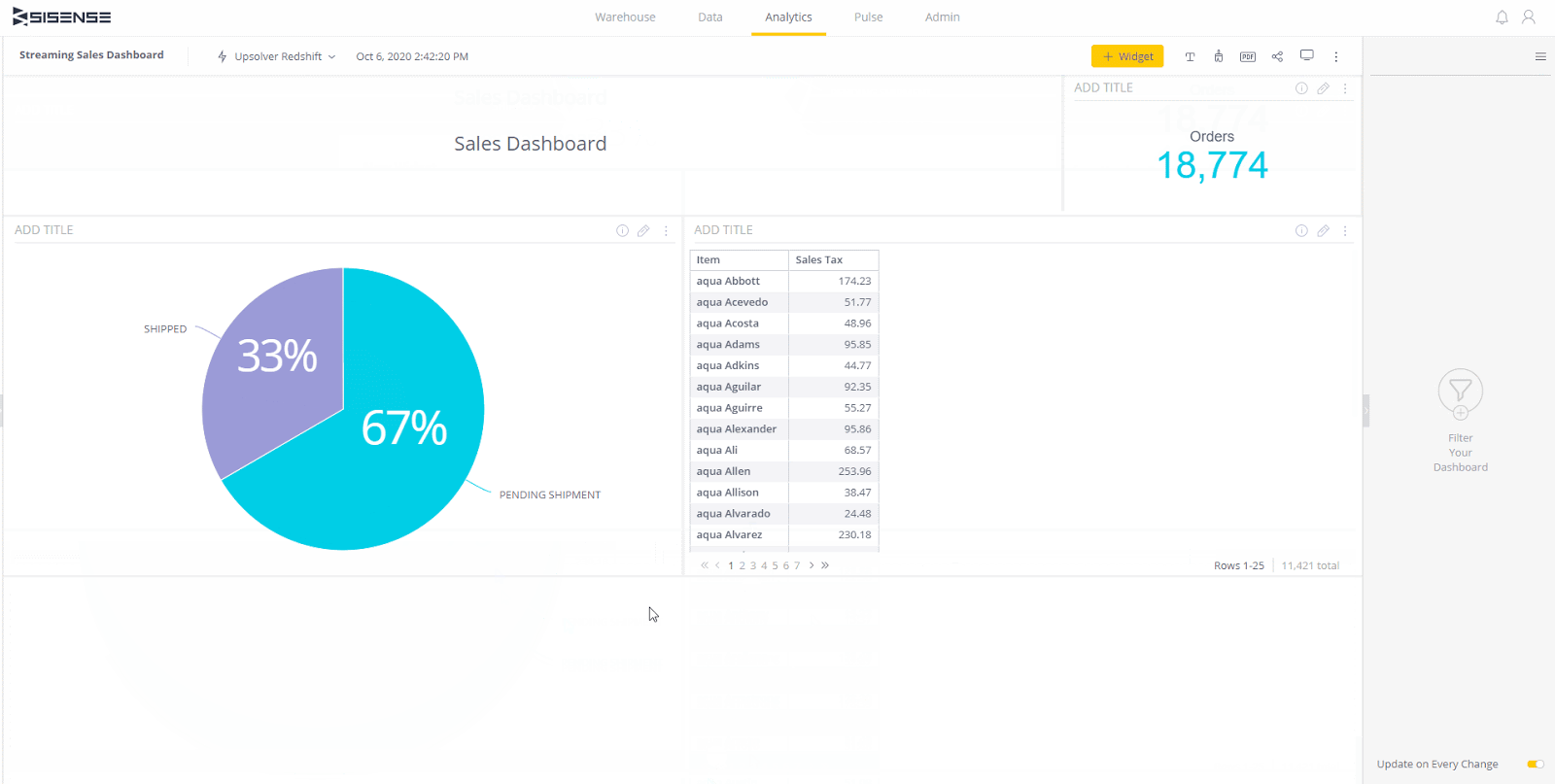
Sie können Ihre Daten jetzt untersuchen. Sie können mit der linken Maustaste auf Elemente des Dashboards klicken, um einen Filter zu platzieren, und mit der rechten Maustaste klicken, um einen Drilldown durchzuführen. Sie können auch mit Filtern im rechten Filterbereich interagieren. Auch hier können Sie nach Feldern in beiden Tabellen filtern, und Sisense ermittelt die richtigen Abfragen für Sie.

Damit Ihre Streaming-Daten für Sie funktionieren
Die Analyse von Streaming-Daten ist für Unternehmen wichtig kritische Entscheidungen in Echtzeit zu treffen. Um dorthin zu gelangen, müssen verschiedene technische Komplexitäten gelöst werden, die durch Streaming entstehen und nicht mit dem Batch-Technologie-Stack behandelt werden. In diesem Artikel haben wir gezeigt, wie Upsolver, AWS und Sisense zusammen verwendet werden können, um eine End-to-End-Lösung für die Streaming-Datenanalyse bereitzustellen, die schnell eingerichtet, ohne Codierung einfach zu bedienen und mithilfe von Cloud Computing / elastisch skalierbar ist. Lager.
Klicken Sie hier, um mehr über Upsolver zu erfahren. Besuchen Sie diese Seite, um Sisense-Plattform-Partner zu werden, und erfahren Sie hier mehr über unsere Partnerschaft mit AWS.


Ori Rafael hat eine Leidenschaft dafür, Technologie zu nutzen und sie für Menschen und Organisationen nützlich zu machen. Vor der Gründung von Upsolver hatte Ori verschiedene Funktionen im Bereich Technologiemanagement in der Elite Technology Intelligence Unit von IDF inne, gefolgt von Unternehmensfunktionen. Ori hat einen B.A. in Informatik und MBA.

Mei Long PM von Upsolver, hatte leitende Positionen in vielen hochkarätigen Technologie-Startups inne. Vor Upsolver spielte sie eine wichtige Rolle in den Teams, die zum Projekt Apache Hadoop, Spark, Zeppelin, Kafka und Kubernetes beigetragen haben. Mei hat einen B.S. in Computer Engineering.
Der Beitrag Streaming-Daten nutzen: Einblicke in Lebensgeschwindigkeit erschien zuerst auf Business Intelligence Online.
Weiterlesen: https://ift.tt/3e6qImt

0 comments:
Post a Comment