

Klicken Sie hier, um mehr über den Autor Paolo Tamagnini zu erfahren.
Die Guided Labeling-Reihe von Blog-Posts begann mit einem Blick auf
wenn eine Kennzeichnung erforderlich ist – d. h. im Bereich des maschinellen Lernens, wenn die meisten
Algorithmen und Modelle erfordern große Datenmengen mit einigen spezifischen
Anforderungen. Diese großen Datenmengen müssen beschriftet werden, um sie zu erstellen
verwendbar. Richtig strukturierte und beschriftete Daten können dann zum Trainieren verwendet werden
und Modelle bereitstellen.
In der ersten Folge unserer Guided Labeling-Reihe Eine Einführung in das aktive Lernen haben wir uns mit dem Human-in-the-Loop-Zyklus des aktiven Lernens befasst. In diesem Zyklus wählt das System zunächst Beispiele aus, die es für das Lernen als am wertvollsten erachtet, und der Mensch kennzeichnet sie. Basierend auf diesen anfänglich beschrifteten Daten wird ein erstes Modell trainiert. Mit diesem trainierten Modell bewerten wir alle Zeilen, für die noch Beschriftungen fehlen, und beginnen dann mit dem aktiven Lernen. Hier geht es darum, auszuwählen oder neu zu ordnen, was der Mensch in der Schleife als nächstes kennzeichnen soll, um das Modell am besten zu verbessern.
Es gibt verschiedene Stichprobenstrategien für aktives Lernen und in
Im heutigen Blog-Beitrag möchten wir uns die Technik der Etikettendichte ansehen.
Etikettendichte
Beim Beschriften von Datenpunkten kann sich der Benutzer über eine der folgenden Fragen wundern
diese Fragen:
- „Is
Diese Zeile meines Datensatzes ist repräsentativ für die Verteilung? “ - „ Wie
Viele andere noch unbeschriftete Datenpunkte ähneln denen, die ich bereits habe
beschriftet? " - " Ist
Diese Zeile ist im Datensatz eindeutig – ist sie ein Ausreißer? “
Die oben genannten sind alles faire Fragen. Zum Beispiel, wenn Sie nur beschriften
Ausreißer, dann ist Ihr gekennzeichnetes Trainingsset nicht so repräsentativ wie Sie
hatte die häufigsten Fälle bezeichnet. Auf der anderen Seite, wenn Sie nur gemeinsam beschriften
In Fällen Ihres Datensatzes würde Ihr Modell immer dann eine schlechte Leistung erbringen, wenn es angezeigt wird
etwas, das nur ein bisschen außergewöhnlich zu dem ist, was Sie beschriftet haben.
Die Idee hinter dem Label
Die Density-Strategie besteht darin, dass Sie beim Beschriften eines Datensatzes dies möchten
Beschriftung, bei der der Feature-Space einen dichten Cluster von Datenpunkten aufweist. Was ist der
Feature-Space?
Feature-Space
Der Feature-Space repräsentiert alle möglichen Kombinationen von Spaltenwerten (Features), die Sie im Dataset haben. Wenn Sie beispielsweise einen Datensatz hätten, der nur das Gewicht und die Größe von Personen enthält, hätten Sie eine zweidimensionale kartesische Ebene. Die meisten Ihrer Datenpunkte hier werden wahrscheinlich etwa 170 cm und 70 kg betragen. Um diese Werte herum ergibt sich also eine hohe Dichte in der zweidimensionalen Verteilung. Um dieses Beispiel zu visualisieren, können wir ein 2D-Dichtediagramm verwenden.
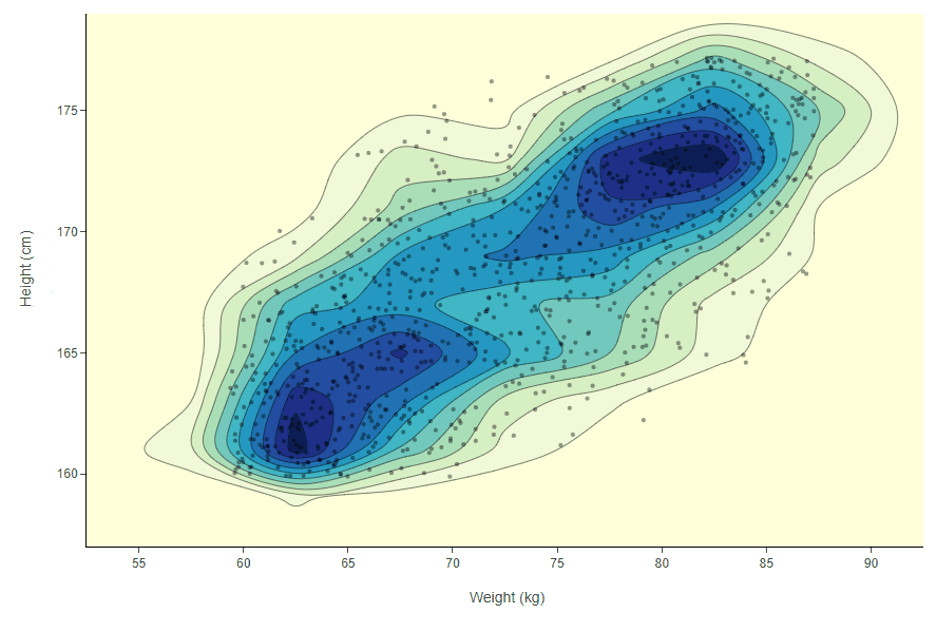
In Abbildung 1 ist die Dichte nicht einfach konzentrisch zu der
Mitte des Grundstücks. In diesem Funktionsbereich befindet sich mehr als ein dichter Bereich.
Auf dem Bild gibt es beispielsweise einen dichten Bereich mit einer hohen Anzahl von
Menschen um 62 kg und 163 cm und ein weiterer Bereich mit Menschen um die 80
kg und 172 cm. Wie stellen wir sicher, dass wir in beiden dichten Bereichen beschriften, und wie würden wir
Diese Arbeit, wenn wir Dutzende von Spalten und nicht nur zwei hätten?
Die Idee wäre, den Datensatz zu untersuchen und zu verschieben
n-dimensionaler Merkmalsraum von dichtem Bereich zu dichtem Bereich, bis wir haben
priorisierte alle gängigen Merkmalskombinationen in den Daten. Messen
Für die Dichte des Merkmalsraums berechnen wir ein Abstandsmaß zwischen einem gegebenen
Datenpunkt und alle anderen, die ihn umgeben, unter Verwendung eines bestimmten Radius.
Euklidisches Abstandsmaß
In diesem Beispiel verwenden wir das euklidische Abstandsmaß über dem gewichteten mittleren subtraktiven Clustering-Ansatz (Formel 1 unten), aber anderen Abständen Maßnahmen können auch verwendet werden. Mit diesem durchschnittlichen Abstandsmaß zu Datenpunkten in der Nähe können wir jeden Datenpunkt nach Dichte ordnen. Wenn wir das Beispiel in Abbildung 1 noch einmal betrachten, können wir jetzt mithilfe der Formel 1 feststellen, welcher Datenpunkt sich in einem dunkelblauen Bereich des Diagramms befindet. Dies ist leistungsstark, da es auch funktioniert, unabhängig davon, wie viele Spalten Sie haben. [19659019] Formel 1: Um den Dichtewert bei der Iteration k der aktiven Lernschleife für jeden Datenpunkt x i, zu messen, berechnen wir diese Summe basierend auf dem gewichteten mittleren Subtraktions-Clustering-Ansatz. In diesem Fall verwenden wir einen euklidischen Abstand zwischen x i und allen anderen Datenpunkten x j innerhalb eines Radius von r a .
Dies Das Ranking muss jedoch jedes Mal geändert werden, wenn wir weitere Labels hinzufügen. Wir möchten vermeiden, immer in denselben dichten Bereichen zu kennzeichnen, und weiterhin nach neuen suchen. Sobald ein Datenpunkt beschriftet ist, möchten wir nicht, dass die anderen Datenpunkte in seiner dichten Nachbarschaft in zukünftigen Iterationen ebenfalls beschriftet werden. Um dies zu erzwingen, reduzieren wir den Rang für Datenpunkte innerhalb des Radius des markierten (Formel 2 unten).
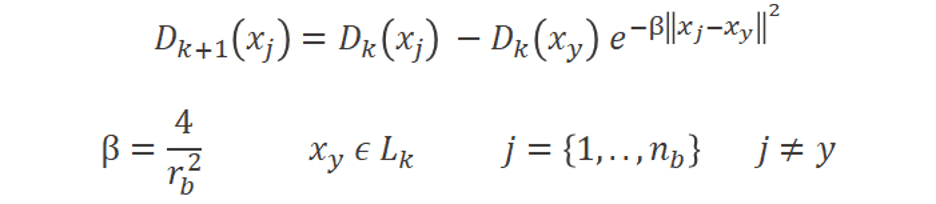
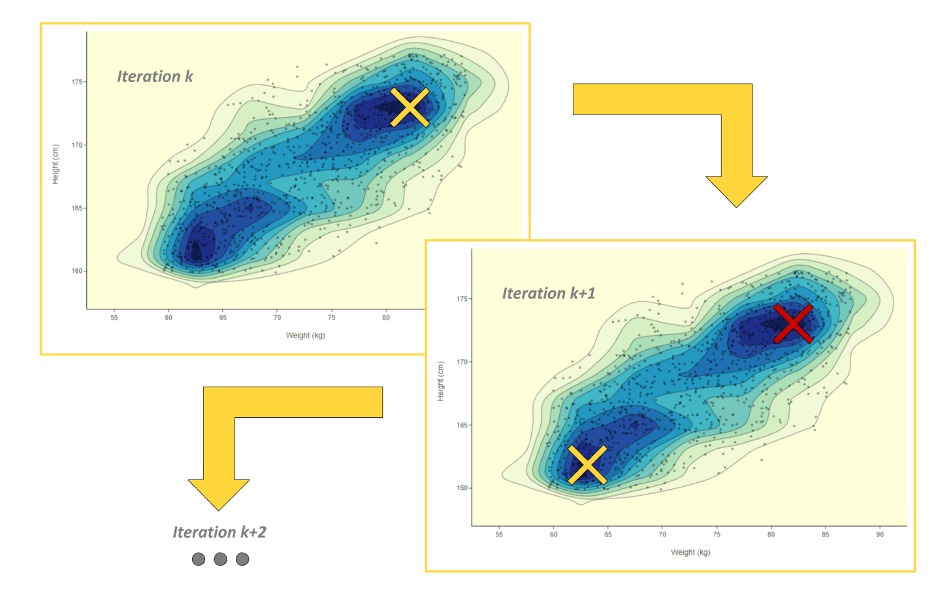
Sobald der Dichterang aktualisiert wurde, können wir das Modell neu trainieren und fahren Sie mit der nächsten Iteration der aktiven Lernschleife fort. In der nächsten Iteration untersuchen wir dank des aktualisierten Ranges neue dichte Bereiche des Merkmalsraums und zeigen dem Menschen in der Schleife im Austausch von Etiketten neue Beispiele (Abbildung 2 unten).
Zusammenfassung
In dieser Episode haben wir uns Folgendes angesehen:
- Etikettendichte
als aktive Probenahmestrategie - Kennzeichnung
in allen dichten Bereichen des Merkmalsraums - Messen
die Dichte des Merkmalsraums mit dem euklidischen Abstandsmaß und
das gewichtete
mittlerer subtraktiver Clustering-Ansatz
Im nächsten Blog-Artikel dieser Reihe werden wir uns damit befassen
Modellunsicherheit. Dies ist eine aktive Abtasttechnik, die auf der Vorhersage basiert
Wahrscheinlichkeiten des Modells für noch unbeschriftete Zeilen. Bald erhältlich!
Der Beitrag Guided Labeling Episode 2: Etikettendichte erschien zuerst auf Business Intelligence Online.
Weiterlesen: https://ift.tt/2CLYhfn

0 comments:
Post a Comment